Unicode, UTF-8
0. Bevezetés
0.0. Indíttatás
Ebben a leírásban megpróbálom összefoglalni a Unicode-dal és UTF-8-cal kapcsolatos talán legfontosabb tudnivalókat. Nem annyira ezen szabványok ismertetése a cél, hanem sokkal inkább egy (szubjektivitást sem nélkülöző) áttekintés arról, hogy miért is volt szükség a megalkotásukra, miért lehet célszerű átállni használatukra, mik a problémák a régimódi ékezetes szövegábrázolásokkal, és mik azok az előnyök és hátrányok, melyeket ezzel szemben a Unicode és UTF-8 nyújtani tudnak. Persze ha még sosem hallottál ezekről a fogalmakról, akkor se keseredj el, a végére remélhetőleg képben leszel.
A nulladik fejezet további része egy kis bemelegedés, meggyőződünk róla, hogy jelen leírást helyesen látod, hiszen a technika ördöge sem alszik.
Az első fejezetben körképet igyekszem nyújtani a Unicode előtti világból, felvázolva azokat a problémákat, melyeket ebben a világban nem lehetett megoldani.
A második fejezetben ismertetem, hogy a Unicode és az UTF-8 milyen gyökeresen új megoldást, sőt új szemléletet nyújtott az első fejezetben látott problémákra.
XXX Itt majd még le kell írnom, hogy hogyan tovább.
0.1. Ékezetteszt
Még mielőtt bármivel is elkezdenénk érdemlegesen foglalkozni, meg kell győződnünk arról, hogy jelen leírást helyesen jeleníti meg az a rendszer, amelyben olvasod. Ez javarészt az alkalmazáson (többnyire böngészőn) múlik, de az operációs rendszer helytelen beállítása vagy hiányos fontkészlet is eredményezhet hibás megjelenítést.
Magyar ékezetek tesztelésére gyakran találkozhatunk az alábbi két kifejezés egyikével:
Persze más nyelvekben másmilyen ékezetes betűkkel találkozunk.
Az olasz például visszafelé dőlő ékezetekkel jelöli a véghangsúlyt. Az alábbi példában egy o és egy e betűt kell látni, rajtuk a magyar nyelvben szokatlan balra dőlő ékezettel. Fogok inni egy kávét.
Franciában az e betűn négyféle ékezet is szerepelhet. Az alábbi példában mind az e, mind az u betű tetején egy kis kalapot (fordított v betűt) kell látni. Biztos benne?
Ha a fenti betűk közül bármelyiket is hibásan láttad, akkor ne folytasd jelen leírás olvasását, mert úgysem értenéd meg, hogy miről lesz szó. Keress másik böngészőt (lehetőleg grafikusat, sokkal jobbak az esélyeid, mint a szöveges terminálban futó böngészőkkel), válassz jobb operációs rendszert, vagy kérd meg a rendszergazdát hogy állítsa be jóra a rendszert.
Jöjjön még néhány nyalánkság. Ha az alábbiakból egy-két jelet esetleg nem jól látsz, az talán betudható a fontkészlet hiányosságainak, de a nagy részüknek jól kell megjelennie.
Ligatúra: o és e betű egybeírva. A szerelem dalára elindult Emmanuelle…
Ez egy euró jel:
Az alábbiak a magyar tipográfia néhány szabályát mutatják be. Más nyelvekre a szabályok eltérhetnek.
A kötőjel rövid és tömzsi, ezt használjuk elválasztásra, toldalék illesztéséhez, szóösszetételeknél stb. Ezzel szemben a nagykötőjel jóval hosszabb és vékonyabb, ezt használjuk például tulajdonnevek kapcsolatának jelölésére, illetve intervallumok megadásakor. A nagykötőjellel azonos írásjel funkcionál gondolatjelként is, ekkor azonban szóköz öleli.
Az idézőjelet alul kezdjük és felül zárjuk, mindkét helyen a 99-es száméval azonos kunkorodással.
Remélem, nem untattalak nagyon itt a bevezetőben. Csíííz :-)
1. Történelmi visszatekintés
1.0. ASCII
A számítógépek bitekkel dolgoznak, a biteket pedig nyolcasával byte-okká (0-tól 255-ig terjedő egész számok) foglalják össze, és ezekkel végeznek mindenféle műveletet, vagy egyszerűen csak továbbítják. Teszik mindezt a mi érdekünkben. Az egyik legősibb, legalapvetőbb igény a számítástechnika felhasználása terén, hogy lehetőség váljon emberek által olvasható szövegek tárolására.
A számítástechnika történetének kezdetén, a '60-as években megalkották az ASCII kódkészletet. Ez a karakterkészlet a 0-tól 127-ig terjedő számértékeknek feleltette meg az angol ábécé kis- és nagybetűit, a számjegyeket, az alapvető fontosságú írásjeleket, valamint számos speciális vezérlő karaktert. Habár más ehhez hasonló karakterkészletek (például EBCDIC) is napvilágot láttak, ezek mára már mind gyakorlatilag kihaltak, az ASCII terjedt el világszerte, mindenütt ezt használják. Ebben például a 72-es értéknek a nagy H, a 101-esnek a kis e, a 108-asnak a kis l, a 111-esnek a kis o felel meg. Ha tehát bárhol a Hello szóval találkozunk, szinte biztosak lehetünk benne, hogy a számítógép valahol mélyen a 72, 101, 108, 108, 111 számsorozattal találkozott, bármilyen számítógépről, bármilyen operációs rendszerről legyen is szó. Amikor erre a honlapra jutottál el, akkor is a honlap részeként egy ilyen számsorozatot töltött le a géped az előző mondatban, amikor annál a szónál tartott.
1.1. 8 bites kódolások
Az ASCII kódkészlet egyáltalán nem alkalmas ékezetes betűk ábrázolására. Mivel egyre nagyobb szükség lett arra, hogy a szoftverek ékezetes betűket is meg tudjanak jeleníteni, megjelentek az ékezetes betűket is támogató karakterkészletek. Ezek a 0-tól 127-ig terjedő értékek terén az ASCII kódtáblával megegyeznek, így garantálják az azzal való kompatibilitást, míg a 128-tól 255-ig terjedő értékekre különféle ékezetes betűket raknak.
Ezzel a megközelítéssel azonban van egy nagy gond. Nevezetesen az, hogy 128-nál lényegesen több ékezetes karaktert és speciálisabb írásjelet találni a különféle latin betűs nyelvekben, és ekkor még az egyéb írásokról nem is beszéltünk.
Megszületett az ISO-8859-1 (más néven Latin-1) karakterkészlet, amely a magyar nyelvből az ő és ű betűket nem tartalmazza, így alkalmatlan magyar szöveg ábrázolására. Megszületett az ISO-8859-2 (Latin-2), amely az összes magyar ékezetet tartalmazza, tehát lényegesen jobb, de a magyar tipográfiának megfelelő nagykötőjel és idézőjelek, valamint sok egyéb fontos szimbólum ebből is hiányzik. Születtek egyéb ISO-8859 kódlapok, a DOS által használt kódlapok (cp437, cp850, cp852 stb.), a Windows karakterkészletei (Windows-1250, Windows-1252 stb.) és sok-sok egyéb is.
A karakterkészlet, mint fogalom tehát nem más, mint byte-ok (számsorozatok) és emberek által olvasható betűk, szövegek között teremtett megfeleltetés. (Zárójeles megjegyzés: nem tiszta a magyar terminológia, ezt a szót használják egy teljesen más fogalomra, a betűk kinézetére is, például Times, Helvetica, Arial stb. Utóbbit én fontkészletnek hívom. Mint nemsokára látni fogjuk, a kettő sajnos nem is mindig válik szét egymástól élesen, ez is problémákat okoz.)
A fenti rendszer pedig szépnek és jónak bizonyult mindaddig, amíg a számítástechnika alatt egymástól teljesen elszigetelt célszoftvereket értettünk, például a külvilágtól elzárt, egy szem gépen futó egy szem könyvelő vagy nyilvántartó programot. De az idők változnak. A speciális célprogramok helyett eltolódott a hangsúly az általánosabb alkalmazások irányába, ahol egyazon szoftvernek kell világszerte sok különböző karakterkészlet-beállítású gépen helyesen működnie. A számítógépeket nem egy, hanem több tucat különféle feladatra használjuk, és rendszeresen kommunikálunk, adatot cserélünk sok más számítógéppel és sok más emberrel a nagyvilágban, online és offline módon egyaránt.
Ugye mindenki találkozott már (sajnos számítástechnikától távolabb
esõ(!) helyzetekben, például újságokban, hirdetésekben,
plakátokon is) azzal a jelenséggel, hogy nincsen dupla ékezet, helyettük az
o és u betûre(!) hullámvonal vagy kalap kerül, mint ebben a
mondatban is? Mi lehet ennek az oka?
Az oka valahol mélyen egészen biztosan az, hogy valaki elkészítette a magyar szöveget a Latin-2 kódolás használatával, és kapott eredményül egy fájlt, amiben az ég-világon minden tökéletes volt, leszámítva egy roppant fontos mozzanatot: nem szerepelt benne az a meta-információ, hogy a byte-ok puszta sorrendje történetesen a Latin-2 karakterkészlet szerint értelmezendő. A következő program pedig Latin-1-ként értelmezte. A byte-ok sorrendje változatlan maradt. A felhasználó által látott szöveg megváltozott.
Régebbi szövegszerkesztőkben találkozni azzal, hogy a karakterkészlet és fontkészlet beállítása egyazon mezőben történik. Leüthetem én a billentyűzetemen a dupla ékezetes magyar Ő jelű betűt, hullámos õ fog megjelenni a képernyőn mindaddig, amíg Times fontkészletet használok. Ha Times helyett Times CE-re váltok, akkor a hullámos õ betűim magyar dupla ékezetes ő-re változnak. Mekkora baromság, ugye? Mi köze egymáshoz a két betűnek? Abszolút semmi, pusztán véletlenül épp ugyanazt a kódot kapták – két különböző karakterkészletben. Az ő legyen mindig ő, az õ pedig mindig õ, akármi is történik, és akármilyen cifra fontkészletet választok.
Hasonló mindennapos jelenség, amikor magyarul látszólag szépen tudó és szép ékezetes betűket rajzoló programok Névjegy (About) ablakában a © jel helyett Š fogad minket. Hejj de jó! Mi történt? A programozó, aki nagy eséllyel angol ajkú és nem sok ékezetes betűt látott még életében, a gépe által használt Latin-1 karakterkészlet táblázatából kikereste a copyright jelet és betette a szövegbe. Csakhogy programja a nyelvi beállításokhoz illeszkedő fontkészletet választ magának, vagyis magyarra beállított rendszeren Latin-1 helyett Latin-2 karakterkészlettel jeleníti meg ugyanazt a bytesorozatot, és míg a 169-es byte a Latin-1 rendszerben a copyright jelet, addig Latin-2-ben a Škoda-betűt jelenti.
De mindez semmi ahhoz képest, amikor egy html fájlban a forrást megnézve a magyar szövegben azt látjuk, hogy „õ” vagy „ô”. Találkoztam már nem egy ilyen oldallal. Vagyis megfelelő idegen szavakkal a napnál is világosabban az van lekódolva, hogy egy o betűre tegyünk egy hullámvonalat, vagy egy u-re egy kalapot. És ez bizonyos rendszereken, bizonyos beállítások mellett képes valóban magyar ő vagy ű betűként megjelenni, mert a Latin-1 karakterkészlet szerint a rendszer a szöveges elnevezést kicseréli a valahányas byte-ra, majd azt megjeleníti Latin-2 kódkészlettel, mert valahol máshol meg ez van beállítva. Nonszensz.
Aki készített már kézzel ékezetes HTML vagy LaTeX fájlt, tudja, hogy megvan a lehetőség a használt karakterkészlet megnevezésére. Magyar dokumentumhoz az iso-8859-2, azaz Latin-2 való. Ezt a html, illetve a tex fájlban meg lehet adni. És mindez teljesen független attól, hogy én a (jó eséllyel terminálban futó) szövegszerkesztő programomban milyen betűt látok, igaz? Lehet, hogy kalapos û betűt látok, de az is lehet, hogy dupla ékezetes ű-t. Ez csak a terminálom beállításain múlik, mindkét esetben egy 251-es byte kerül a fájlba. Ettől teljesen függetlenül, ha latin1 argumentummal töltöm be a TeX inputenc csomagját, akkor kalapos û-t fogok nyomtatásban kapni, ha viszont latin2 argumentumot adok neki, akkor magyar ű-t. Micsoda hülyeség! Szeretnék magyar és francia vagy olasz tex fájlokat is készíteni, sőt akár vegyes nyelvűeket is, mondjuk egy szótárat, de nem akarom úton-útfélen a terminálom beállításait változtatgatni. Miért kellene tudnom, hogy melyik nyelvhez milyen kódkészlet passzol? Miért kellene tudnom, hogy ha kalapos û-t látok a magyar tex fájlban, az nem baj, mert megmondtam, hogy latin2, és ezért nyomtatásban már magyar ű betű fog megjelenni? Nem, köszönöm, ebből én nem kérek. Én azt szeretném, hogy a nyomtatott papíron – akármilyen nyelven is dolgozom éppen – az a karakter jelenjék meg, amit a terminálban a gépelés során látok. Ha kalapos û-t látok a terminálban, akkor az azért került oda, mert én kalapos û-t akartam látni, és ennek érdekében explicite egy kalapos û-t vittem be valahogy a gépbe, tehát természetesen nyomtatásban is kalapos ékezetet várok. Ha viszont magyar billentyűzetkiosztásra váltok át, és leütöm az Ű feliratú gombot, akkor mind a fájl szerkesztése során, mind a nyomtatásban végig dupla magyar ékezetes ű betűt szeretnék látni, nem mást.
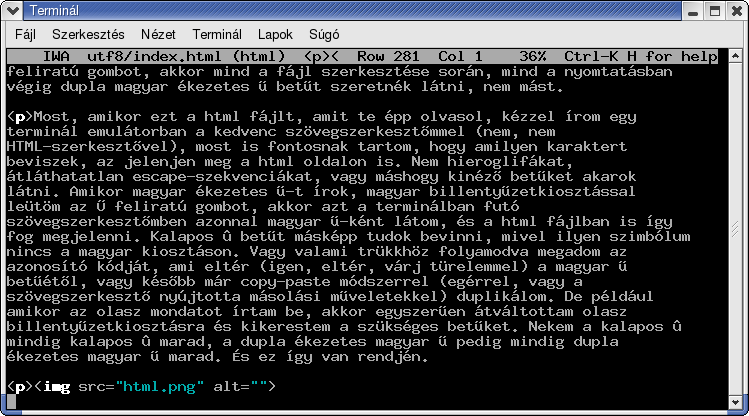
Most, amikor ezt a html fájlt, amit te épp olvasol, kézzel írom egy terminál emulátorban a kedvenc szövegszerkesztőmmel (nem, nem HTML-szerkesztővel), most is fontosnak tartom, hogy amilyen karaktert beviszek, az jelenjen meg a html oldalon is. Nem hieroglifákat, átláthatatlan escape-szekvenciákat, vagy máshogy kinéző betűket akarok látni. Amikor magyar ékezetes ű-t írok, magyar billentyűzetkiosztással leütöm az Ű feliratú gombot, akkor azt a terminálban futó szövegszerkesztőmben azonnal magyar ű-ként látom, és a html fájlban is így fog megjelenni. Kalapos û betűt másképp tudok bevinni, mivel ilyen szimbólum nincs a magyar kiosztáson. Vagy valami trükkhöz folyamodva megadom az azonosító kódját, ami eltér (igen, eltér, várj türelemmel) a magyar ű betűétől, vagy később már copy-paste módszerrel (egérrel, vagy a szövegszerkesztő nyújtotta másolási műveletekkel) duplikálom. De például amikor az olasz mondatot írtam be, akkor egyszerűen átváltottam olasz billentyűzetkiosztásra és kikerestem a szükséges betűket. Nekem a kalapos û mindig kalapos û marad, a dupla ékezetes magyar ű pedig mindig dupla ékezetes magyar ű marad. És ez így van rendjén.
Amit a fenti képen látsz, azt hagyományos 8 bites karakterkészlettel nem lehet megcsinálni. Légy türelemmel, nemsokára fény derül a megfejtésre.
A sokfajta karakterkészlettel az is gond, hogy képtelen egy általunk kiválasztott karakterkészleten kívüli karakterek ábrázolására. Ha magyar szöveget írunk, akkor is bármikor szükségünk lehet a Latin-2 karakterkészletből hiányzó szimbólumra is (például idegen tulajdonnévben lévő ékezetes betű, copyright jel, euró jel stb.). De bármikor megeshet, hogy egy francia nyelvű levélre kívánunk az eredeti sorok beidézése mellett magyarul válaszolni és máris gondban vagyunk.
Ezt teszi még súlyosabbá az a technikai körülmény, hogy a rendszerben használt karakterkészletet sok esetben csak a rendszergazda tudja megadni, vagy legalábbis a felhasználó részéről hatalmas szaktudást igényel az átállítása. Természetesen nemhogy ez a hatalmas szaktudás nem várható el az átlag felhasználótól, hanem még az sem, hogy tisztában legyen a Latin-2 és hasonló fogalmak jelentésével. Az átlagos felhasználó azt akarja, hogy ha leüt egy adott betűt, akkor az a betű mindig, minden körülmények között változatlan maradjon. Ha egy magyar ő betű bárhol átalakul hullámos õ-vé, az elfogadhatatlan. Ennél többet nem akar tudni a felhasználó, és nem is szabad, hogy szüksége legyen ennél nagyobb tudásra. A többit oldják meg a szoftverfejlesztők.
De, mint láttuk, a sokfajta karakterkészlet megközelítésnek az a legsúlyosabb problémája, hogy byte-okban gondolkodik, nem betűkben. Kit érdekel, hogy milyen byte-ok vannak a háttérben? Senkit. Mindenkit az érdekel, hogy melyik emberi kultúra melyik írásjelét látja a képernyőn.
Természetesen a jelenlegi áldatlan állapot nem a felhasználóknak, hanem a figyelmetlen, nemtörődöm fejlesztőknek köszönhető, vagy még inkább azoknak a fejlesztőknek, akiket az egész problémakör nem érdekel, és még mindig nem látják, hogy nincsenek rendben a dolgok.
2. Unicode, UTF-8
2.0. Indíttatás
Azok kedvéért, akik átugrották volna az előző, hosszúra nyúlt fejezetet, ismételjük át a három legfőbb tanulságot:
2.1. A Unicode
A nemzetköziséget is egyre jobban támogató szoftverek kifejlesztése során teljesen egyértelműen kiderült, hogy a karakterkészletek tarkasága a számítástechnika fejlődésének egyik hatalmas zsákutcája, hiszen nem képes kielégítő megoldást nyújtani számtalan problémára. A megoldást csakis egy olyan kódolás nyújthatja, amely egymagában képes az összes nyelv összes karakterét ábrázolni.
Meg is született, sőt, állandóan fejlődésben van egy ilyen kódkészlet, a Unicode, UCS (Universal Character Set), avagy ISO-10646 szabvány. (Megjegyzés: ez egy tájékoztató, ismeretterjesztő iromány, nem precíz specifikáció. Nem fogok belemenni olyan apróságokba, hogy egészen pontosan mi is a Unicode és mi az UCS és mi az ISO-10646 és mi köztük a különbség, mert ez most számunkra nem lényeges.)
Nyilván ez csak úgy lehetséges, ha átlépjük a 256-os határt, vagyis azt mondjuk, hogy minden karakternek megfeleltetünk egy egyedi pozitív egész azonosító számot, ami (szinte) tetszőlegesen nagy lehet. Eleinte még úgy képzelték, hogy 216 (65536) elég lesz, de később letettek erről, és most a bombabiztos 231 (bő kétmilliárd) az elvi határ, ugyanakkor a becslések szerint 221 (bő kétmillió) fölé nem fognak eljutni a számokkal, ennyi jócskán elég lesz az összes elő, halott és mesterséges kultúra írásjeleinek ábrázolására.
Az összes korábbi 8 bites kódkészletben megtalálható karakter belefért a Unicode kezdeti alsó 65536-os tartományába, amelyet Basic Multilingual Plane-nek (BMP) is neveznek.
Az alsó 128 érték megegyezik a hagyományos ASCII-val. Sőt, az alsó 256 megegyezik a Latin-1-gyel. A magyar ő és ű betűk tehát 256-nál nagyobb azonosítót kaptak. Önálló azonosítót kapott minden egyes írásjel, melyekkel például a jelen leírás nulladik fejezetében találkoztunk, így például van alsó 99-es idézőjel, van felső 99-es, felső 66-os stb., mind-mind különböző azonosítóval.
A Unicode értékeket általában hexadecimálisan, nagy ritkán decimálisan adjuk meg. Sokszor U+ bevezetés után írjuk le a hexa értéket legalább 4 számjegyen (itt látszik még a régi idők szele, amikor úgy képzelték, ennyi elég lesz). Például az ó betű kódja U+00F3 (decimális 243), az ő betűé pedig U+0151 (decimális 337).
A Unicode egy ennél sokkalta bonyolultabb szabvány. A különféle egzotikusabb betűírásokon (cirill, héber, arab stb.) túl tartalmazza a kínai, japán, koreai (ezeket együtt szokták angolul CJK-nak rövidíteni) írásjeleket, és számos vezérlő karaktert, melyekkel például a jobbról balra írás kapcsolható be és ki, vagy éppen a sortörés lehetséges helyei adhatók meg. Ezekkel ebben a leírásban nem foglalkozom.
2.2. Unicode fájl?
A hagyományos 8 bites karakterkészletek a betűket és a byte-okat rendelték össze, így teljesen egyértelmű volt egy adott karakterkészlet használata esetén, hogy hogyan kell egy szöveget fájlban eltárolni, vagy a fájlt visszaalakítani szöveggé. A karakter (írásjel) és az őt ábrázoló byte fogalma összemosódott, szinte egy és ugyanaz volt.
A Unicode nem karakterek és byte-ok között teremt kapcsolatot, hanem karakterek és nemnegatív egész számok között, ami egészek gyakran olyan nagyok, hogy nem is férnének el egy byte-on. Most már fontos tehát tisztázni egy fogalmat: a karakter szó a (tágabb értelemben vett) írásjel (a speciális vezérlő parancsokat is megengedjük) szinonimája, vagyis nem a byte-é.
Szóval ott tartottunk, hogy a Unicode a karakterek (írásjelek) és a nemnegatív számok között létesít összerendelést. Ezek a nemnegatív számok egyelőre lógnak a levegőben, nincsenek még sehogyan sem eltárolva. Hogyan lehet akkor őket bárhogyan ábrázolni, memóriában dolgozni velük, fájlban tárolni, hálózaton (byte-okat továbbító csatornán) átküldeni?
A helyzet az, hogy nem létezik önmagában olyan fogalom, hogy Unicode fájl. A Unicode szabvány nyitva hagyja azt a kérdést, illetve többféle lehetőséget is nyújt annak megválaszolására, hogy ezeket a számokat hogyan is ábrázoljuk.
A Unicode lelkivilágú programok, például szövegszerkesztők minden bizonnyal 4 byte-ot foglalnak minden egyes írásjel memóriában történő eltárolására. Így egy egymillió leütést tartalmazó dokumentum nem 1MB-ot, hanem 4MB-ot igényel a rendszer memóriájából. Probléma ez a mai számítógépekkel? Nyilván a legkisebb mértékben sem. Talán diszkre is így mentik a fájlt, amennyiben saját formátumot használnak. (Jó kérdés, hogy little endian vagy big endian ábrázolással, tehát a legkisebb vagy a legnagyobb helyiértékű byte kerül előre.) Talán tömörítik, talán nem. Ez a formátum természetesen nem kompatibilis az ASCII-val, de ha ez a program saját belső formátuma, akkor ez senkit sem érdekel.
Ha a számítástechnika ma indulna útjára, akkor talán nem 8, hanem 32 bitet fognánk össze egy egységként, talán ugyanígy byte-nak hívnánk, és talán mindenhol a Unicode fenti ábrázolási formáját használnánk. De nem ez a helyzet, és egy ilyen gyökeres kérdésben a számítástechnikát nem lehet a régi énjével totálisan inkompatibilis módon átalakítani, még évtizedek leforgása alatt sem. Éppen ezért a Unicode ezen ábrázolási formája nagyon sok helyen nem használható.
Azokban a helyzetekben, amikor különböző alkalmazások vagy rendszerek között cipelünk információt, a Unicode szabvány UTF-8 ábrázolási módját tudjuk messze a leghatékonyabban használni.
2.3. Az UTF-8 ábrázolásmód
Az UTF-8 ábrázolási mód a következőképpen fest: Az ASCII karaktereket egy byte-on, önmagukkal reprezentáljuk, ezek tehát 128 alatti értékű byte-ok. A 128-nál nagyobb vagy egyenlő kódú Unicode karaktereket viszont több egymást követő 128-nál nagyobb vagy egyenlő byte ábrázol. Érdekességképpen a táblázat, így kell a biteket átrendezni:
Unicode érték UTF-8 bytesorozat
1. byte 2. byte ...
30 0 7 0 7 0 ...
| | | | | |
00000000 00000000 00000000 0xxxxxxx <-> 0xxxxxxx
00000000 00000000 00000xxx xxxxxxxx <-> 110xxxxx 10xxxxxx
00000000 00000000 xxxxxxxx xxxxxxxx <-> 1110xxxx 10xxxxxx 10xxxxxx
00000000 000xxxxx xxxxxxxx xxxxxxxx <-> 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
000000xx xxxxxxxx xxxxxxxx xxxxxxxx <-> 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0xxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx <-> 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Az x betűk által jelzett biteket azonos sorrendben kell átpakolni a
túloldalra. Minden Unicode karaktert a legkorábbi ráhúzható szabály szerint
kell UTF-8-ra átalakítani. Így például az ó betű (Unicode kódja decimális
243, hexadecimális 0x00F3, bináris 00000000 00000000 00000000 11110011) legkorábban a
második szabályra húzható rá, tehát UTF-8 kódja bináris 11000011 10110011, vagyis egy
decimális 195, azaz hexa 0xC3, majd ezt követően egy decimális 179, azaz
hexa 0xB3 byte.
Talán már nem okozok vele meglepetést, ez a html fájl, amit most olvasol, UTF-8 kódolást használ. A múltkori Hello példát folytatva most tehát, ha leírom az ékezetes Helló szót, akkor amikor a géped éppen itt tartott a letöltésben, akkor a 72, 101, 108, 108, 195, 179 bytesorozatot kapta meg ezen oldal részeként.
Az UTF-8 ábrázolási mód a következő említésre méltó tulajdonságokkal rendelkezik:
Így néz ki az, amikor egy UTF-8 kódolású fájlt Latin-2 kódolású
terminálban jelenítünk meg:
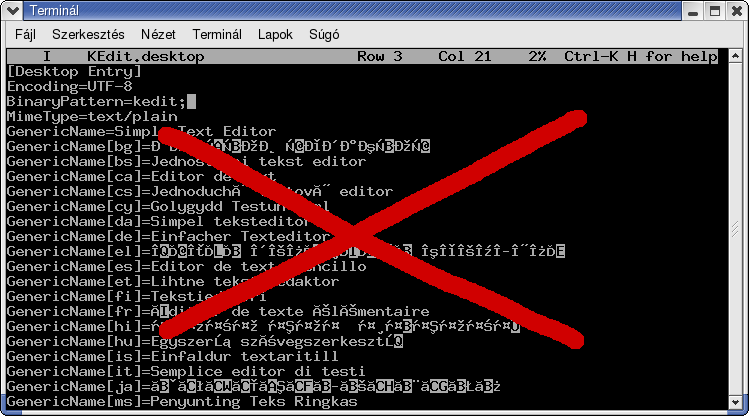
Ne tessék megijedni, a Unicode és az UTF-8 nem erről szól. Mint az előbb
említettem, egymással inkompatibilis beállítások okozzák ezt a jelenséget.
Így néz ki ugyanaz a fájl UTF-8 kódolásra állított terminál és
UTF-8-at helyesen kezelő szövegszerkesztő használatával:
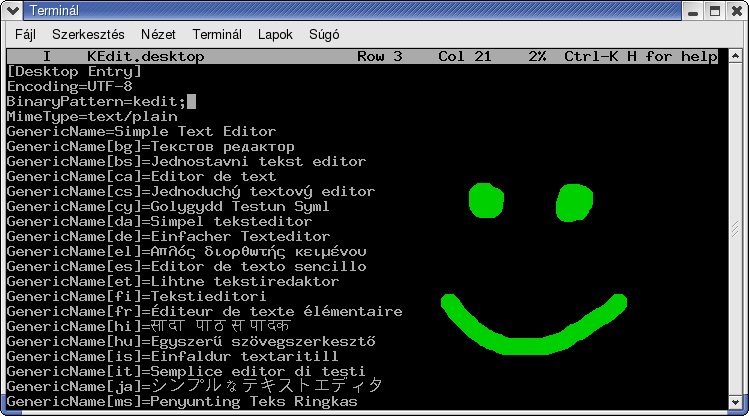
Ugye szép?
Természetesen mindazok a programok, melyek a régi 8 bites filozófiában készültek, alkalmatlanok UTF-8 kódolású szövegek kezelésére. Az alkalmazásokat fel kell készíteni annak megértésére, hogy például ha UTF-8 kódolású terminálban dolgoznak, akkor több byte-ot kiküldve csak egyet lép a kurzor (de vannak dupla széles betűk is, lásd a fenti ábrát), és hasonlóan több érkező byte együtt jelenthet egy karaktert. Szövegszerkesztők számára szokatlan körülmény az is, hogy felülírásos módban egy „a” betű „á”-ra cserélése változtat a fájl hosszán. Éppen ezért sajnos találkozni még bőven olyan programokkal, melyek egyáltalán nem képesek az UTF-8 kódolást kezelni.
2.4. A jövő
Sokan még nem látják, de sokan már igen: a jövő egyértelműen a Unicode-é, azon belül is a felhasználó által inkább látható helyeken, vagyis a fájlok tartalmában, hálózati kommunikációban stb. a Unicode UTF-8 ábrázolásáé.
Ezen leírás készítésekor néhány Linux disztribúció már szinte mindenütt átállt az UTF-8 karakterkészlet használatára. A kritikus pont a terminálok viselkedése, hiszen ez szabja meg leginkább, hogy a felhasználó milyen kódolással látja a szövegfájlokat, az új fájljait milyennel hozza létre és így tovább. A többi disztribúció is hamarosan, néhány éven belül egészen biztosan át fog állni. Legjobb tudomásom szerint sok egyéb elismert rendszer, például MacOS, Windows, Java is erősen a Unicode vonalat szorgalmazza.
Fentebb még azt írtam, hogy nincsen értelme annak, ha van egy bytesorozatunk, de nem tudjuk, hogy azt milyen karakterkészlet szerint kell értelmezni. Ez továbbra is változatlanul teljesül, jóllehet, megindult egy folyamat, melynek eredményeképpen az UTF-8 lesz „a” karakterkészlet. Ha egy rendszer mindenütt UTF-8-at használ, akkor már nincsen szükség ezen meta-információ úton-útfélen történő cipelésére.
3. UTF-8 a gyakorlatban
Ebben a fejezetben igyekszem áttekintést nyújtani az UTF-8-at korrektül kezelő programokról, elsősorban Linux platform esetén.
3.0. Terminál kontra grafikus felület
Technikai okok miatt élesen meg kell különböztetnünk a maguknak grafikus ablakot nyitó programokat a terminálban futó programoktól.
Grafikus programoknak könnyű dolguk van. Ők maguk mondhatják meg minden egyes képernyőpixelről, hogy ott mi álljon, így elvileg a rendszer extrém módon elrontott beállításai mellett is van esélyük helyes UTF-8 kezelésre. Természetesen általában ezek a programok sem közvetlenül maguk végzik el a teendőket, hanem egy UTF-8-at helyesen kezelő grafikus elemkészletre bízzák ezt a teendőt. Manapság két ilyen elterjedt grafikus elemkészlet található meg Linux rendszereken, az egyik a QT, a másik pedig a GTK+ 2-es verziója. Azon alkalmazások, amelyek ezek egyikét használják, szinte mind UTF-8 lelkivilágúak, hiszen a GTK+-nak vagy a QT-nek mindig UTF-8 kódolású szöveget kell odaadniuk. A háttérben ezen elemkészletek elvégzik a szükséges teendőket, például ha nem találnak Unicode fontkészletet, akkor hagyományos Latin-1, Latin-2 stb. kódolású fontkészletekből okosan összelapátolják a megjelenítendő betűket.
A fentiektől eltérő grafikus elemkészletet (például Xlibs, Athena, Motif vagy klónja stb.) használó alkalmazások roppant valószínűtlen, hogy helyesen kezelnék az UTF-8-at, mivel alattuk hagyományos 8 bites karaktermegjelenítő motor található.
Érdekes átmenet a GTK+ 1-es verziója, amelyik a locale beállításokhoz igazodva képes hagyományos 8 bites és UTF-8 módban is viselkedni.
A terminálban futó programoknak ezzel szemben jóval nehezebb dolguk van, hiszen igazodniuk kell egy alattuk lévő rendszer, a terminál adottságaihoz és tulajdonságaihoz. Nincsen könnyű dolga egy olyan terminálban futó szövegszerkesztőnek, amelyik szeretné mind UTF-8, mind hagyományos 8 bites terminálban, mind UTF-8, mind hagyományos 8 bites kódolású fájl szerkesztése esetén kihozni a lehető legtöbbet.
3.1. A terminál helyes nyelvi beállítása
Az egyes terminálok valahogyan viselkednek, de sajnos ezt az információt az alkalmazások nem tudják közvetlenül magától a termináltól lekérdezni. Ezt az információt környezeti változókból derítik ki. Az operációs rendszer összerakóinak a feladata, hogy ezeket a változókat helyesen beállítsák, és a felhasználó felelőssége, hogy ne rontsa el.
A „locale charmap” parancs kiírja a megfelelő környezeti változók tartalma alapján a vélt karakterkészletet.
Az értéket az LC_ALL, LC_CTYPE és LANG környezeti változók közül az első olyan határozza meg, amelyik valamilyen értékre be van állítva. Tehát ha LC_ALL be van állítva (az „echo $LC_ALL” parancs kiír valamit), akkor az határozza meg, ha nem, akkor az LC_CTYPE a következő, és ha az sincs beállítva, akkor a LANG. Ezekben a változókban azonban nem tudunk közvetlenül karakterkészletet megnevezni, hanem csak nyelvet, és módosítóként karakterkészletet.
A változók értéke nyelv_ország[.kódkészlet][@egyébmódosító] szintaxisú, ahol a szögletes zárójel opcionális értéket jelöl. Tehát például a „hu_HU” a magyar nyelvet jelenti Magyarország területi beállítással, és a magyarhoz alapértelmezett ISO-8859-2 karakterkészlettel. Ugyanakkor a „hu_HU.UTF-8” érték magyar nyelvet, Magyarországot és UTF-8 karakterkészletet jelent. Hasonlóan a nyelvi beállítás értéke lehet például „en_US” (USA, ISO-8859-1), „en_GB” (Nagy-Britannia, ISO-8859-1), „cs_CZ” (cseh, Csehország, ISO-8859-2), „ja_JP” (japán, Japán, EUC-JP) stb., és ezek bármelyike megtoldható a „.UTF-8” kódkészlet-módosítóval.
Természetesen a fent említett „locale charmap” parancs is ezen változókat figyeli, így például egy „export LC_ALL=hu_HU.UTF-8” kiadása után a „locale charmap” UTF-8-at fog válaszolni.
Az összes jól megírt terminálban futó program szintén ezt az információt használja fel a terminál viselkedésének kiderítéséhez, és ehhez igazítja saját működését. Fontos tehát, hogy ez az érték a terminál tényleges viselkedését tükröző módon legyen beállítva. Ha ez esetleg nem így van, akkor reménytelen helyes működést várnunk a terminálban futó programoktól.
3.2. Terminál emulátorok
A gnome-terminal (Gnome legalább 2-es verziója esetén) szerintem a legkorrektebb. Indulásakor a megfelelő környezeti változókhoz passzoló kódolást választ, ugyanakkor ez futás közben is megváltoztatható, kétféleképp is, a fenti menüsorból, valamint escape-szekvenciák kiírásával: az „ESC %G” escape-szekvencia UTF-8 módba kapcsolja a terminált, míg az „ESC %@” visszakapcsolja 8 bites módba. Fontos azonban, hogy a vte (ez a tényleges terminál motor, a gnome-terminal csak a körítés (menük és társai) e köré) legalább 0.11.12-es változata legyen telepítve, a 0.11.11-es verzióval bezárólag egy súlyos hiba miatt UTF-8 módban gyakran szétesik a képernyő tartalma.
A konsole (a KDE terminálja) mindössze annyival rosszabb a Gnome termináljánál, hogy menüben nem lehet átállítani (és megtekinteni) a karakterkészletet. Induláskor ez is igazodik a környezeti változókhoz, és a fenti escape-szekvenciákkal ebben is átállítható a működés.
Hagyományos xterm. A viselkedés számtalan roppant bonyolult módon beállítható és parancssorból is szabályozható, de egy dologban minden beállítás megegyezik: működés közben sem menüből, sem escape szekvenciával nem állítható át. Habár a Ctrl+jobbegérklikk menüben van UTF-8 opció, és ez bizonyos beállítások mellett még át is állítható, több órányi doksiolvasás és próbálkozás során sem sikerült belőle kicsikarnom a Gnome és KDE termináljához hasonló módon a menet közbeni állíthatóságot. A legtöbb, amit el sikerült érnem, az az, hogy induláskor igazodjon a környezeti változókhoz, és ennek megfelelően viselkedjen 8 bites vagy UTF-8 módban. Ehhez az erőforrás-fájlban (/etc/X11/app-defaults/XTerm, avagy ~/.Xdefaults) az -iso8859-X karakterkészletek helyett mindenütt -iso10646-1 karakterkészletet adjunk meg, természetesen legyen telepítve ilyen font, valamint adjunk meg egy „*locale: true” sort is.
rxvt: létezik rxvt-unicode projekt, erről többet nem tudok.
Linux konzol. VGA mód esetén esélye sincs egy igencsak korlátos karakterkészleten kívüli elemek megjelenítésére. Framebuffer esetén nem tudom, hogy van-e erre lehetőség, vagy ekkor is csak egy szűk fontkészlet betűit tudja egyszerre megjeleníteni. Ennek ellenére valamelyest képes UTF-8-at kezelni, tehát ha előre tudjuk, hogy csak magyar karaktereket szeretnénk ábrázolni, ámde UTF-8 kódolásban, akkor ezt meg tudjuk tenni. A környezeti változók terén kicsavart a helyzet. Míg a grafikus terminálok tulajdonképpen felhasználói folyamatok (processzek) a rendszerben, amik kapnak környezeti változókat, addig a Linux szöveges konzolok nem processzek, hanem a kernel szerves részei, melyek már az előtt is léteznek, hogy a felhasználó bejelentkezik rájuk. Tehát környezeti változók egyáltalán nem képesek ennek viselkedését befolyásolni. Alapból 8 bites, a unicode_start és unicode_stop szkriptekkel (melyek lényegében a fent megismert escape-szekvenciát küldik ki és beállítanak valamiféle fontot) válthatunk UTF-8 és 8 bites mód között. A szkripteket okosan kell paraméterezni (vagy átírni) ahhoz, hogy valami használható fontot töltsenek be. A problémakör ennél még jóval szerteágazóbb, a kernelt és pár egyéb programot is illik picit megpatchelni ahhoz, hogy minden tökéletes legyen.
PuTTY (Windows). Nagyon korrekt. A kódolás (köztük UTF-8) a beállítások ablakban Window/Translation alatt állítható be, így célgépenként más-más érték is elmenthető. Futás közben mind escape szekvenciával, mind a beállítások ablak előhívásával (ablak címsorán jobb klikk, Change Settings) megváltoztatható a karakterkészlet. Apró eltérés a gnome-terminalhoz képest, hogy ha alapvetően Latin-X terminálban escape szekvenciával váltunk át ideiglenesen UTF-8-ra, akkor a beállítások ablak ezt az információt nem tükrözi, az az alap (8 bites) kódkészletet mutatja.
3.3. Szövegszerkesztők
3.3.1. Terminálban futó szövegszerkesztők
A vim egész szépen működik. A karakterkódolás az encoding, fileencoding és termencoding változókkal (lásd nemsokára a gvim-et) állítható be. A három változó egész pontos szerepével nem vagyok teljesen tisztában, ha csak kettő lenne, azt érteném. Sajnálatos, hogy engedi a terminál vélt karakterkészletét is átállítani, nem lenne szabad, ily módon nehézkes rábeszélni, hogy Latin-2 terminál fölött UTF-8 fájlt szerkesszünk vele.
XXX emacs?
A joe 2-es verziói reménytelenek, a 3.0-s egész tűrhető UTF-8 támogatással rendelkezik, a 3.1-es pedig gyönyörűen kezeli az UTF-8-at. Minden joe-használónak melegen ajánlott legalább a 3.1-es változatra frissíteni. Szépen lehet vele Latin-X terminál fölött UTF-8 kódolású fájlt, vagy éppen UTF-8 terminál fölött Latin-X kódolású fájlt is szerkeszteni. A terminál kódolását a rendszer nyelvi beállításaiból szedi, nem lehet felülbírálni, ez így jó és bölcs, mert nem szabad, hogy erre szükség legyen. A fájl kódolását a ^T E billentyűvel tudjuk megadni (TAB segít a választásban). A ^K space billentyű megmondja a kurzor alatt lévő betű kódját, UTF-8 módban az UCS értéket mindenféle számrendszerben.
XXX mined, ne, le, ...
Az mcedit-hez (mc-hez) és a pico-hoz a neten lehet patchet összevadászni. A hivatalos verzió még nem támogatja az UTF-8-at, de már létezik használható folt.
3.3.2. Grafikus szövegszerkesztők
A Gnome 2 grafikus környezet tartozékaként elérhető gedit, valamint a KDE grafikus környezettel szállított kate és kwrite szövegszerkesztőkkel nem okozhat gondot UTF-8 kódolású fájl szerkesztése. Új fájl készítése esetén a mentéskor választhatjuk ki a kívánt kódolást. Fájl megnyitásakor jó eséllyel magától felismerik, hogy az UTF-8 kódolású, de ha mégsem, akkor egy kattintással át tudjuk állítani a menüben. A fent felsorolt programok közül UTF-8 kódolású fájl szerkesztésére a gedit-et ajánlom, mivel kisebb az erőforrásigénye, és a Gnome vonal jobban szorgalmazza a mindenütt UTF-8-ra átállást, mint a KDE vonal.
A gvim a 6.1-es verzióval bezárólag csak GTK+ 1-et tudott használni, a 6.2-es verziótól kezdve a GTK+ 1-es és 2-es változatával is lefordítható. A GTK+ 2-höz fordított változata gyönyörűen kezeli az UTF-8-at, a GTK+ 1-et használó változatról nincsen információm. A beolvasott fájl karakterkészlete a „:set encoding=utf-8” paranccsal állítható be.
XXX emacs?
Jelen sorok írásakor az xedit, nedit reménytelenek.
3.4. Levelezők
3.4.1. Terminálban futó levelezők
A mutt, amennyiben okosan van lefordítva (sajnos le lehet fordítani bután is – az „ldd `type -p mutt`” parancs kimenetében „libncursesw.so”-t kell látni, a lényeg hogy a „w” betű legyen ott a „libncursesw” végén, ekkor jó) és okosan is van bekonfigurálva (az /etc/Muttrc illetve ~/.Muttrc fájlban a „set charset=...” opciónál helyesen adjuk meg a terminál karakterkészletét, vagy még inkább sehogyan sem adjuk meg, mert ekkor igazodik a megfelelő környezeti változókhoz), az esetben gyönyörűen kezel mindenféle karakterkódolást, Latin-X és UTF-8 kódolású terminálban futva egyaránt megpróbálja kihozni a lehető legtöbbet a terminál adottságaiból, bármilyen kódolásban is érkezett a levél. Érdemes UTF-8 terminált használni, ekkor minden tökéletes. Mindezektől függetlenül a Muttrc-ben a send_charset opcióban felsorolhatunk kódolásokat, a kimenő levelet a legelső olyan készlettel fogja elküldeni, amelyre veszteségmentesen átalakítható. Ha itt az iso-8859-2 kódolást az utf-8 előtt említjük meg, azzal elősegítjük a régi levelezőprogramok számára is felfogható módon történő kommunikációt.
A pine 4.60-as verziójában jelent meg minimális támogatás arra, hogy Latin-X terminálban UTF-8 kódolású levelet képes legyen megjeleníteni. Ezt követően leveleztem az egyik fejlesztővel, kiderült, hogy UTF-8 terminál támogatása nem szerepel terveik között, nincsen rá erőforrásuk. A kimenő levél karakterkészletét a konfigurációs fájlban kell megadnunk. Ez a karakterkészlet-információ nem más, mint egy csupasz sztring, amit bután bebiggyeszt a levél elejére, tehát esze ágában sincs esetleges ettől eltérő karakterkészletű terminál esetén a byte-okat okosan átalakítani. Szánalmasan régi felfogású, katasztrofális ékezetkezelésű program. Ugyanakkor lehet hozzá patchet találni a neten, amitől jó lesz.
3.4.2. Grafikus levelezők
XXX
3.5. Böngészők
XXX
3.5.1. Terminálban futó böngészők
XXX
3.5.2. Grafikus böngészők
XXX
3.6. LaTeX
XXX inputenc
3.7. Segédeszközök
XXX recode, iconv
XXX ttyconv, luit
3.8. Tippek és trükkök
A GTK+ 2-es változatát használó programokban (például gedit, gvim, gnome-terminal, mozilla, galeon, epiphany, evolution, balsa stb.) a Ctrl és Shift billentyűk egyidejű nyomva tartása közben begépelhetjük egy karakter Unicode értékét hexadecimálisan. A gépelt értéket ideiglenesen aláhúzottan vagy kis téglalapban látjuk, majd a Ctrl és Shift elengedését követően az alkalmazás úgy tesz, mintha ezt az egyetlen Unicode karakterkódot kapta volna a billentyűzetről. Tehát például Ctrl+Shift+171 eredménye egy ű betű.
4. Dokumentumformátumok
4.1. LaTeX
LaTeX-ben az encoding csomag képes különféle beviteli kódlapok meghatározására. Például ha egy ilyen sort helyezünk el a fájl fejlécében:
\usepackage[latin2]{inputenc}
akkor a fájlt Latin-2 kódolással értelmezi a rendszer.
\usepackage[utf8]{inputenc}
sor esetén UTF-8 kódolást használhatunk a fájlban. Ez a kiegészítés azonban
csak nemrégiben jelent meg a TeX rendszerekben. Az egyik legnépszerűbb
TeX-összeállítás, a teTeX a 3-as verziójában már tartalmazza, a 2.0.2-es
verzióból még hiányzik. A 2-es verzióhoz beszerezhető és pillanatok alatt
telepíthető innen: http://www.unruh.de/DniQ/latex/unicode/,
illetve a használt Linux disztribúció csomagjai között is érdemes
körülnéznünk, tetex-unicode, latex-ucs vagy hasonló nevű csomag után
kutatva.
Természetesen az ékezetek és egyéb speciális jelek escape szekvenciákkal is megadhatók, ezek szintaxisa azonban a TeX rendszerre specifikus egyedi jelölésmód (akár az ékezetek megadásánál p\'eld\'aul erre gondolunk, akár a két aposztrófból összerakott idézőjelre vagy a két mínuszjelből összerakott nagykötőjelre), míg ha ezek UTF-8 megfelelőjét használjuk, akkor az gond nélkül ültethető át másmilyen formátumba, például html-be.
4.2. E-mail
Egy e-mail fejlécébe ha belekukkantunk, ilyesmi sorokkal kell találkoznunk:
MIME-Version: 1.0 Content-Type: text/plain; charset=ISO-8859-2Ezek határozzák meg a levél tartalmának típusát. A MIME-Version sor kötelező, azért mert csak. (Ennek hiányában sok levelező kliens figyelmen kívül hagyja a Content-Type értéket.) A Content-Type pedig jelenlegi példánkban azt mondja, hogy a levél tartalma egy Latin-2 kódolású sima szöveg. Hasonló szintaxissal az egyes csatolmányok típusa is megadható.
A fejléc sorok megadása különösen abban az esetben kritikus, amikor valaki nem levelezőprogramból, hanem például szkript segítségével küld leveleket. Nem elég, ha a küldő tudja, hogy ő milyen kódolással készítette el a fájlt, ezt az információt el kell juttatnia a címzetthez is, hiszen a címzett levelezőkliense nem gondolatolvasó.
Ettől teljesen függetlenül létezhet egy Content-Transfer-Encoding, ami egy feljebbi rétegként a bytesorozatot átalakítja valahogyan, annak érdekében, hogy hálózaton jobban továbbítható legyen ősrégi (például 7 bites) levelező szervereken át is. Ennek semmi köze nincs ahhoz, hogy a levél tartalma egyszerű szöveg-e, és ha igen, akkor milyen karakterkészletű. Talán jobb lett volna, ha nem is említem meg.
A fejléc soraiban, például tárgy és feladó, szintén megadhatók ékezetek, szintén a karakterkészlet megnevezésével együtt, bonyolult szintaxisban.
Sajnálatos módon a levelezők terén a legnagyobb a káosz, nagyon kevés levelezőprogram van, pláne a régebbiek és a terminálban futók közül, amelyek helyesen kezelik a karakterkészlet-információt. Mindennaposak az olyan levelezők, amelyek a bytesorozatot tartják meg változatlanul mondjuk a válaszolás során a beidézett részben, elfelejtve annak karakterkészletét, és a végén hozzábiggyesztik a konfigurációs fájlunkban megadott karakterkészletet. Az eredmény nyilván katasztrofális. Meg egyébként is, tegyük fel, hogy kapok egy levelet, Latin-1 kódolással, olasz balra dőlő ékezetes betűkkel, szeretnék rá válaszolni magyarul, de az én rendszerem meg Latin-2-vel dolgozik, mi legyen? Nyilván csak az UTF-8 jöhet szóba a kimenő levél karakterkészleteként. Csak sajnos kevés levelezőprogram van, amelyik ezt ilyen jól tudja.
Az e-mailekben a fejlécben megnevezett karakterkészleten kívül eső karakterek megadására nincsen lehetőség.
4.3. HTML
Na ez se kispálya.
A karakterkészlet információt kétféleképpen is meg lehet adni.
Az egyik lehetőség a HTTP fejlécben az e-mail esettel azonos módon a Content-Type használata. Sajnos ez az adat a kommunikáció során viszonylag el van rejtve a felhasználó elől, elég nehéz kideríteni, ezt még az előtt egyezteti a kliens és a szerver, hogy a honlap tényleges tartalmát (tipikusan a html fájlt) elkezdené küldeni. Lássunk egy példát, szeretném kideríteni a képzeletbeli http://www.foo.bar/bigyo.html oldal karakterkészletét. Kiadom a
telnet www.foo.bar 80parancsot (a 80-as az alapértelmezett http port, telnet helyett pedig lehetne netcat parancs is), majd begépelem ezt:
GET /bigyo.html HTTP/1.1 Host: www.foo.barItt megadhatnék egyéb adatokat is, de nem teszem, és egy újabb Enterrel (vagyis üres sor bevitelével) tudatom, hogy készen vagyok. Erre a szerver valami ilyesmit válaszol (kivonat):
HTTP/1.1 200 OK Content-Type: text/htmlmajd ő is egy üres sort követően közli a tényleges oldal tartalmát. De az is lehet, hogy ilyesmit válaszolt:
HTTP/1.1 200 OK Content-Type: text/html; charset=UTF-8
Hát íme. Vagy mondott karakterkészletet, vagy nem.
Ha mi készítjük a honlapot, és nem tetszik az adott érték, akkor, amennyiben Apache web szerver fut Unix rendszeren, a honlap mellett helyezzünk el egy .htaccess nevű fájlt ilyesmi tartalommal:
AddDefaultCharset UTF-8vagy
AddCharset UTF-8 .html .txtés próbáljuk újra. Vagy bejött, vagy nem. A fenti példa azt mondja, hogy minden fájl, vagy csak a html és txt fájlok karakterkészleteként UTF-8-at küldjön ki a szerver. De sajnos elképzelhető, hogy a rendszergazda nem engedélyezi, hogy felülbíráljuk a rendszer alapértelmezett értékét. Ez esetben sajnos nincsen lehetőségünk arra, hogy honlapunk mellé korrektül megmondjuk, milyen karakterkészlettel értelmezendő, tehát rugdossuk a rendszergazdát.
Ha kézzel írunk cgi szkriptet, akkor ott nekünk kell a fejléc sorokat is kiíratnunk, így annak helyes beállítása nem jelenthet gondot.
PHP szkriptünket kezdjük valahogy így:
<?php
header("Content-Type: text/html; charset=UTF-8");
?>
A karakterkészlet HTTP fejlécben történő megnevezésének előnye, hogy nemcsak html, hanem sima szöveg esetén is használható. Hátránya, hogy a honlap készítője részéről nehézkes a beállítása, és ha valaki tükrözi vagy diszkre letölti az oldalt és onnan nézi meg, akkor elvész ez az információ.
A karakterkészlet megnevezésére a másik lehetséges hely már a html fájlon belül van, így azt látjuk, amikor készítjük a fájlt. A <head> szekción belül elhelyezhetünk egy ilyen sort is:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">Ez azt jelenti, hogy vedd úgy, mintha a HTTP fejlécben ezt a Content-Type sort kaptad volna.
Ennek a megközelítésnek hátránya, hogy csak html esetén használható, előnye, hogy a honlap tükrözése, letöltése során is megmarad.
Na és akkor ehhez képest most jön a hatalmas idétlenség. Egyrészt a legtöbb webszerver alapból megnevezi a Latin-1 karakterkészletet (ugyan miért ezt?), esetleg ha jobb formában van, akkor az UTF-8-at, de megnevez valamit, ritka, amelyik nem. Másrészt ha mindkét lehetséges helyen szerepel karakterkészlet-információ, akkor a HTTP fejlécben lévő számít, a html oldal <meta> elemét hagyják figyelmen kívül a böngészők. Ez szerintem egy hatalmas tervezési hiba.
Az opera böngésző, amennyiben az oldal kis fülecskéje fölé visszük az egeret, buboréksúgóban megjeleníti az oldal értelmezéséhez használt karakterkészletet.
Szerencsére html fájlban megvan a lehetőség arra, hogy a használt karakterkészletbe nem illeszkedő karaktert is megnevezzünk. Sok karakternek létezik &valami; típusú neve, de Unicode értéket is írhatunk, &#dec; vagy &#xhex; alakban, például ű = ű. Így elvileg akár az összes ékezetes betűt is ábrázolhatjuk. Előny, hogy ekkor nem számít, mit kavarunk a karakterkészlettel, hátrány viszont a komoly méretnövekedés, valamint hogy webböngészőn kívül gyakorlatilag olvashatatlan a fájl, a TeX ilyen id\'etlen \'ekezetei p\'eld\'aul igaz\'an kisp\'aly\'asak ehhez az őrültséghez képest.
5. Vége
5.1. Irodalomjegyzék
Hivatalos Unicode honlap. Itt aztán mindent megtalálsz, bár főleg száraz technikai leírásokat. http://www.unicode.org/
Markus Kuhn UTF-8 és Unicode FAQ-ja elsősorban, de nem kizárólag Unix/Linux rendszerekre kihegyezve. Nagyon jó összefoglaló. Az URL-t nehéz megjegyezni, mégis könnyű az oldalra rátalálni: a Google keresőnek beírjuk hogy UTF-8 FAQ, majd tizenkilencre lapot húzunk (I'm feeling lucky, jó napom van). http://www.cl.cam.ac.uk/~mgk25/unicode.html
Joel Spolsky fantasztikusan élvezetes, olvasmányos, kissé ironikus hangvételű írása, nagyjából arról, amiről itt az első két fejezet foglalkozott, vagyis hogy mi a gond a régi rendszerekkel és mi a Unicode lényege. Jóval rövidebb, mint amit én dobtam össze. Élmény elolvasni, kötelező olvasmány mindenkinek. http://www.joelonsoftware.com/articles/Unicode.html Ja, egyébként Joel összes többi írását is ajánlom figyelmedbe, nagyon jók!
5.2. Mindenmás
Ezen leírás eredeti lelőhelye a http://www.cs.bme.hu/~egmont/utf8/ oldal.
Nem törekszem 100%-os precizitásra, ugyanakkor sok helyen saját szubjektív véleményemet sem rejtem véka alá. A dokumentum a készítésekori állapotot türközi, elképzelhető, hogy azóta megváltoztak a dolgok, például általam szapult program immár helyesen kezeli az UTF-8-at. Az esetleges hibákért semminemű felelősséget nem vállalok.
A dokumentum magán célra tetszőleges módon felhasználható.
Elektronikus úton történő terjesztése, közzététele az alábbiak figyelembevételével lehetséges. Ha csak részletet közölsz, akkor is szerepelnie kell az eredeti változatra mutató linknek. Szerepelnie kell annak az információnak, hogy nem a te írásodról van szó. Amennyiben online módon elérhetővé teszed az oldalt, az esetben meg kell győződnöd róla, hogy szervered vagy „text/html” (karakterkészlet megnevezése nélkül), vagy pedig „text/html; charset=UTF-8” MIME-típus megnevezésével szolgálja ki, és ha tudomást szerzel róla, hogy ez esetleg valamiféle technikai probléma miatt megváltozott volna, akkor a hiba kijavításáig haladéktalanul el kell távolítanod a másolatot.
Anyagi ellenszolgáltatás fejében történő közzététel, illetve nyomtatott formában történő bármilyen (nonprofitot is beleértve) terjesztés csak a szerzővel előzetesen kötött írásbeli megállapodás esetén lehetséges.
Készítette: Koblinger Egmont <egmont kukac cs pont bme pont hu>
Első verzió: 2004. szeptember.
Utolsó módosítás: 2005. szeptember.