Next: 6. Az ETS rendszer Up: Deklaratív nyelvek oktatásának támogatása Previous: 4. A jelenleg használt Tartalomjegyzék
A jelenleg használt programok ismertetését követően rátérhetek a szakdolgozatom magját képező részre, egy új, egységes rendszer tervének ismertetésére. Hogy tisztábban lássuk a rendszer feladatát, céljait, elsőként megkísérlem elhelyezni az oktatást támogató rendszerek világában, és felfedem, hogy mit jelent a fejezet címében használt ETS rövidítés. Ezt követően rátérek a rendszer részletes tervére, amelyet egy átfogó képtől a részletek felé haladva ismertetek. A tervezés során végig törekszem arra, hogy a rendszer lehetőleg tárgyfüggetlen legyen, sőt bizonyos részek esetében még azt sem használom ki, hogy programozási nyelvek oktatásáról van szó. Azokon a pontokon, ahol egy-egy tervezési döntés meghozatalához konkretizálni kell a feladatot a tárgyra vagy akár a két deklaratív nyelv egyikére, ott ezt külön jelzem.
A tervezés során általában nem használom ki, hogy milyen eszközökkel fog megvalósulni a rendszer. Ahol - bizonyos részletkérdéseknél - ezt mégis megteszem, ott többnyire a Prolog nyelvet fogom javasolni. Ennek okai a következők:
Amint látni fogjuk, a rendszer által ellátandó funkciók tulajdonképpen egy tanársegéd feladatainak felelnek meg. Éppen ezért az Elektronikus Tanársegéd, azaz ETS elnevezést javaslom. Az ETS rövidítés előnye, hogy emlékeztet a közismert ITS-re, és több olyan angol név is adható, amelynek szintén ez a rövidítése, mint például englishElectronic Tutoring System vagy englishEnvironment for Training Students. A továbbiakban az ETS betűszóval fogok hivatkozni a tervezendő rendszerre.
A jelenleg használt programokról szóló fejezetet olvasva talán már az olvasóban is kialakulhatott az a vélemény, hogy a tervezendő rendszer nem sorolható be egyik kategóriába sem cha:okttam. fejezetben említettek közül. Mielőtt azonosítanám a rendszer feladatait, elsőként azokra a különbségekre szeretném felhívni a figyelmet, amelyek egy új kategória, az ETS létrehozását indokolják.
A BME-n a képzés a hagyományos előadótermi stílust követi, és ezen a Deklaratív programozás tárgy oktatói sem szeretnének változtatni. Az ITS-ek esetében azonban teljes értékű oktatásról, új ismeretanyag átadásáról van szó, nem pedig a már - elméletileg - meglévő megerősítéséről és gyakoroltatásáról. Az említett tanuló-modellre a mi esetünkben nincsen szükség, hiszen nem kell nyomon követnünk egy-egy hallgató fejlődését és előrehaladását, hanem elegendő bizonyos jól definiált szinteken ellenőrizni a tudás meglétét. Ennyiben tehát egy ITS több. Ugyanakkor az ITS-ek nem látnak el olyan feladatokat, mint például a házi feladatok ellenőrzése, vagy a félév során megszerzett pontok összesítése. Erre ott nincs is szükség, hiszen a kurzus elvégzése nem áll másból, mint az ITS összes tesztjének megfelelő szintű teljesítéséből, nálunk azonban más a helyzet.
Az új rendszer - elsődleges - célja és feladata nem az, hogy az előadótermi munkát könnyítse, hanem hogy a háttérmunkákat lássa el minél önállóbban. Órai demonstrációkat az oktatók már most is tartanak: egy-egy szárazabb vagy nehezebben emészthető témakörnél színesítik az elhangzottakat azzal, hogy ,,élesben'' is bemutatják az adott algoritmus vagy nyelvi eszköz működését. Ehhez azonban nincs szükség másra, mint egy Prolog- vagy SML-értelmezőre és egy pár frappáns példaprogramra.
A gyakoroltatás a tervezendő rendszer fontos - talán legfontosabb - részét képezi, e tekintetben tehát talán leginkább a CAT rendszerekhez hasonlítható. Ugyanakkor nem statikus, azaz például a házi feladatok félévről félévre változnak, és ezeket a változásokat természetesen tükrözni kell a rendszerben is. A tervezés egyik célja, hogy az ilyen frissítések a lehető legkevesebb emberi munkát igényeljék, ezt azonban teljesen nem lehet megspórolni. Természetesen egy CAT rendszer is változhat, mégis az ilyen változások inkább a rendszer fejlesztését, fejlődését jelentik, nem pedig az üzemeltetésből adódnak.
A rendszerünk másik fontos feladata az adminisztratív teendők támogatása. Ez a feladatkör semmiképpen sem sorolható a CAT rendszerek által lefedett területhez.
A különbség ezen a ponton már annyira magától értetődő, hogy talán nem is kellene magyaráznom. Mégis érdemesnek tartom megemlíteni, hogy a rendszer a tervek szerint csak olyan adminisztratív feladatokat fog ellátni, amelyek a NEPTUN-ból valamilyen okból kimaradtak. A NEPTUN által ellátott feladatok kapcsán ugyanakkor szükséges lehet a két rendszer közötti együttműködés, amelybe a hallgatók névsorának átvételétől a vizsgajegyek visszaírásáig bezárólag sok minden belefér.
sec:dek-okt. fejezetben alaposan megvizsgáltuk az oktatás egyes eszközeit és a hozzájuk kapcsolódó, automatizálható feladatokat is. Ezek a feladatok a tervezendő rendszer egy-egy funkciójaként jelennek majd meg. Most az osztályozhatóság kedvéért ismét tekintsük át őket, ezúttal kissé más megvilágításban.
A fő tennivalókat alapvetően két csoportba lehet osztani, bár egy-két esetben nehéz lehet eldönteni, hogy az adott feladat melyik csoportba is tartozik. A két csoport egyikébe a programozási nyelvhez szorosabban kapcsolódó tennivalók tartoznak, mint például a beküldött programok vagy a gyakorló feladatokra adott megoldások ellenőrzése. A másik csoportba az alapvetően adminisztratív jellegű teendők tartoznak, mint például a ZH- és vizsgafeladatokra adott pontszámok nyilvántartása. Ez a felosztás abban is a segítségemre lesz, hogy amikor szükséges, megállapíthassam, hogy mely tennivalók függetleníthetők teljesen a tárgytól, és melyek nem. Most viszont segít láttatni, hogy az ETS feladatköre valóban egy tanársegédé. Nézzük át még egyszer, címszavakban, hogy melyek ezek a feladatok!
A tervezés során elsőként azt kell eldönteni, hogy a létrehozandó ETS rendszer alapvető szerkezete milyen legyen. Lehetséges lenne egy monolit rendszer létrehozása is, én azonban - és ezzel, azt hiszem nem vagyok egyedül - sokkal jobbnak és rugalmasabbnak tartom a moduláris, kisebb komponensekből építkező architektúrákat, ezért ezúttal is ezt a módszert választom. Ha pedig modulokból építkezünk, meg kell állapítani, hogy pontosan milyen komponensekre lesz szükség, s csak ezután láthatunk neki a részletek kidolgozásának. Ebben a részben erről lesz szó.
Nyilvánvaló, hogy minden feladat alapvetően egyes hallgatókhoz kapcsolódik, ha úgy tetszik, az adatműveletek legnagyobb önálló egysége a hallgató. Az egyes feladatok is csak és kizárólag a hallgatókon keresztül kapcsolódnak egymáshoz, pontosabban szólva a hallgatók által elért eredményeken keresztül. Az egyetlen logikus következtetés ezekből a megfigyelésekből az, hogy az új rendszer lelke csakis egy, a hallgatók adatait, elsősorban pontszámait nyilvántartó adatbázis lehet. Ez az az egységes, közös adatbázis, ami jelenleg hiányzik, ezért sem állhattak össze a más-más funkciójú komponensek rendszerré. A komponensek közül elsőként tehát magát az adatbázist érdemes megtervezni, összegyűjteni a benne tárolandó értékeket és kialakítani a szerkezetét. Egy jól megtervezett, a jelenlegi funkciókat kiszolgáló, a jövőbeni bővítéseknek teret hagyó adatbázis létfontosságú, ha jól működő, könnyen fenntartható és menedzselhető rendszert akarunk kapni.
A központi adatbázishoz kapcsolódik a többi komponens, amelyek - a moduláris felépítésnek köszönhetően - tetszőleges programozási nyelven valósíthatók meg (akár komponensenként más-más nyelven), és ízlés szerint módosíthatóak a rendszer élete során mindaddig, amíg az adatbázison keresztül megfelelő módon tartják a kapcsolatot a többi komponenssel. Hogy melyek ezek a komponensek, azt legjobban a feladatok analizálásával és csoportosításával tudjuk megállapítani.
ssec:etsfel. fejezetben a tananyaggal kapcsolatban három feladatot azonosítottunk. Mivel ez a három feladat lényegesen különbözik egymástól, logikusnak látszik, ha három külön komponenst rendelünk hozzájuk. Az adminisztratív feladatok közül néhány szorosan kapcsolódik ezekhez, ezért azt javaslom, hogy az ilyen feladatokat is ide soroljuk. Közülük egyeseket - mint például a hallgatók értesítését - szükséges lehet többfelé osztani, hiszen több komponenshez is kapcsolódnak. A megmaradó, valamint az adatbázis létéből adódó újabb adminisztratív feladatokat rendeljük egy negyedik, tisztán adminisztratív komponenshez. Ekkor a következő négy komponens alakul ki:
Az alábbiakban mind a négy komponensről szólok pár szót, mielőtt belefognék a részletes megtervezésükbe.
A komponens legnagyobb részét az a program teszi ki, amelynek jelenleg is van egy jól működő megvalósítása. Mégis érdemes a teljes komponens felépítését újra átgondolni, a következők miatt:
Természetesen ide tartozik a házi feladatok beadását lehetővé tevő program, a webfelületen keresztül a teszteredményekhez hozzáférést biztosító CGI szkript, valamint a hasonlóságvizsgálatot megoldó program is.
Ez a programegyüttes legfiatalabb tagja, kísérleti stádiumban. Ebből adódóan újratervezésről nem lehet szó, hiszen nincsenek mérvadó tapasztalatok a használatával kapcsolatban. Az oktatóknak ugyanakkor határozott elképzeléseik vannak a funkcióját, működésének főbb jellemzőit illetően, így ez alapján, valamint a már elkészült programrészekben felhasznált ötleteken okulva elfogadhatóan pontos tervek készíthetők egy ideális alrendszerről.
A névre szóló feladatlapok generálásától eltekintve ez a komponens alapvetően adminisztratív jellegű, a feladatok többségét a központi adatbázishoz kapcsolódó egyszerű adatfeltöltő és lekérdező program el tudja látni. A generáláshoz viszont szükség van egy jól szervezett feladatkészletre is, amelynek feltöltéséhez ugyan lehet segítséget nyújtani, mégis alapvetően emberi munka.
Természetesen a többi komponens is olvassa és módosítja az adatbázist, ahogy éppen szükséges. De ez a komponens az, amelyik hasznosítja is, hiszen rajta keresztül érhetők el a benne tárolt értékek. Fontos, hogy a hallgatók meg tudják nézni az eddig megszerzett pontjaikat, ill. hogy az oktatók különböző szempontok szerint csoportosítva le tudják kérdezni az évfolyam egészére vagy az egyes hallgatókra vonatkozó adatokat. Mindezt egy webfelületen keresztül a legcélszerűbb elérhetővé tenni. E mellett az adatbázisban tárolható még számos olyan információ, amely nem pontszám-jellegű - ezek módosítását és lekérdezését is itt kell megoldani.
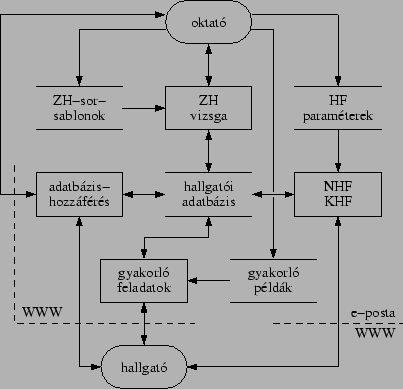
A központi adatbázison kívül több adatbázisszerű állomány szükséges az egyes komponensek működéséhez. Ezen adatbázisok, a két fő felhasználói csoport (hallgatók és oktatók), valamint a komponensek kapcsolódását fig:komp. ábra mutatja. Az ábrán a négy fő komponenst négy téglalap reprezentálja, ezek mind kapcsolódnak a központi szerepet betöltő, két párhuzamos vonallal jelölt adatbázishoz. A négy komponens közül háromhoz egy-egy további adatbázis kapcsolódik, amelyekben paraméterek, bemeneti adatok vannak, ezeken keresztül hangolható az egyes komponensek viselkedése. A lekerekített sarkú téglalapok jelölik a hallgatókat és az oktatókat, akik jól definiált felületen keresztül férnek hozzá az egyes komponensekhez, ill. az adatbázisokhoz. A hozzáférés két felületét, nevezetesen a Webet és az elektronikus levelezési felületet külön jelöltem egy-egy szaggatott vonallal, a nyilak az adatok áramlásának irányát jelzik.
Az adatbázis létrehozásának alapvető célja, hogy a hallgatók által megszerzett pontszámokat egy helyen összegyűjtve lehessen tárolni. Ennek megfelelően az adatbázis mezőinek döntő többsége valamelyik pontszámot fogja tárolni. Ha azonban már amúgy is van egy adatbázisunk, kézenfekvő ötlet minden egyéb járulékos adatot is itt tárolni. Ezen adatok egy része olyan, hogy magának a hallgatónak kell tudnia (be)állítani, mások csak az oktatók által hozzáférhetők.
Miért van szükség ezekre a mezőkre? Ha az oktatók szeretnének valamit közölni a hallgatókkal, azt könnyen megtehetik, akár előadáson, akár a tárgy honlapján, akár a tárgyhoz rendelt elektronikus levelezési listán keresztül. A fordított irányú információáramlás azonban nehézkesebb. A hagyományos módszerek közé tartozik a különböző ívek körbeadása és az elektronikus levélen keresztüli információgyűjtés, azonban mindkettőnek megvan a maga hátránya. Az ívek körbeadásával az a gond, hogy érthető módon csak azok tudnak föliratkozni, akik jelen vannak az előadáson (vagy megkérik valamelyik előadás-járó barátjukat). Az oktatóknak küldött elektronikus levelek pedig feleslegesen lekötik az oktatók figyelmét kézhez vételükkor, később pedig körülményes a névsor összeállítása. Nos, a hátrányokat talán kissé eltúloztam, hiszen ezek azért gyakran alkalmazott és alapvetően jól bevált módszerek, de a saját tapasztalatom az, hogy a webes regisztráció mindig lényegesen hatékonyabb és a hallgatók körében is népszerűbb. A BME Híradástechnika Tanszékén például - Mihály Zsigmondnak köszönhetően - a különböző mérésekre való jelentkezés egy ügyes webfelületen keresztül van megoldva, így a hallgatók akkor és onnan jelentkeznek, amikor és ahonnan csak akarnak (feltéve persze, hogy van Internet hozzáférésük), ezáltal elkerülhető a felesleges sorbanállás is. A lényeg tehát az, hogy ha biztosítunk egy webes felületet a különböző jelentkezések lebonyolítására, és az igényeket bevisszük az adatbázisba, az a hallgatók és az oktatók szempontjából is kedvező.
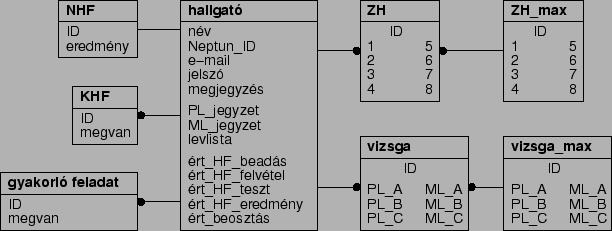
Az adatbázis szerkezetének kialakításakor természetesen a Deklaratív programozás tárgy struktúrájából indultam ki. Első lépésként egy olyan adatbázist terveztem, amely képes tárolni a jelenleg alkalmazott számonkérés-fajták eredményeit, illetve egy-két járulékos információt a hallgatóról. Ennek eredményét mutatja fig:dbspec. ábra, amelynek részletes ismertetésétől eltekintek. Bemutatásával az a célom, hogy láthatóvá tegyem, hogyan jutottam el a végeredményként kapott általános struktúrához. Az ránézésre is jól látszik, hogy ez a szerkezet nagyon szorosan kötődik a jelenlegi tárgystruktúrához, és a kisebb változásokat is nehezen lenne képes követni.
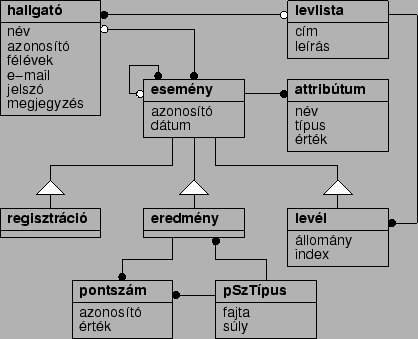
A végső struktúráról áttekintést nyújtó entitás-reláció diagram látható fig:db. ábrán. Hogy milyen tartalmat takarnak az egyes mezőnevek, és hogy az egyes relációk számossága miért pont az, ami, egyelőre nem fontos, de mindenre fény derül a továbbiakban az adatbázis tartalmának részletezésekor. Az áttekinthetőség érdekében osszuk az adatbázis mezőit három fő csoportra, és vizsgáljuk őket külön-külön. Ez a három csoport a személyes adatok csoportja (ebbe a hallgató nevű entitásban tárolt mezők tartoznak), a különböző események adatait rögzítő mezők csoportja, és végül a levelezési listát adminisztráló mezők csoportja.
Az adatbázis alapját azok a mezők képezik, amelyek a hallgatók azonosítására szolgálnak. Ezek az alábbiak:
Az adatbázis magját a félév közben bekövetkező különféle események adatai alkotják. Amint hamarosan látni fogjuk, az események több fajtáját különböztethetjük meg. Ezen fajták közös jellemzőinek leírására szolgál az esemény entitás, amelynek két mezője van:
Egyes események más eseményekhez is kapcsolódhatnak, ezt jelzi a visszahurkolódó ,,nulla-vagy-egy - több'' reláció. E kapcsolat értelme nyilvánvalóan függ az adott esemény jellegétől.
Az eseményekhez ún. attribútumok is tartozhatnak, amelyekkel az adott esemény tetszőleges adatát le tudjuk írni, ezek tárolására szolgál az attribútum entitás. Minden attribútumnak van egy
Most nézzük meg, hogy melyek lehetnek az eseményfajták. A jelenlegi
tárgystruktúrában hármat tudtam értelmes módon elkülöníteni, de ez nem
jelenti azt, hogy a későbbiekben ne lehetne ennél többet is
megkülönböztetni. A különböző fajtákat leíró entitások ,,is-a'' relációban
állnak az esemény entitással, azaz mindegyik rendelkezik ez utóbbi
összes jellemzőjével, és ehhez adnak hozzá továbbiakat (minimálisan azt az
információt, hogy milyen eseményfajtáról van szó).
A legegyszerűbb eseményfajta az ún. regisztráció. Ez az esemény teszi lehetővé a fejezet bevezetőjében is említett, a hallgatóktól az oktatók felé irányuló információáramlást . Az ezt leíró entitásnak nincsenek további mezői, hiszen az esemény azonosítója elegendő a regisztráció tárgyának megadásához, szükség esetén azonban kapcsolódó attribútumokkal tetszőleges paraméter megadható. Ilyen entitásban a jelenlegi tárgyszerkezet mellett a következők adminisztrálását tudom elképzelni:
Talán a legfontosabb eseményfajta a hallgató által elért eredmény. Ennek segítségével tároljuk a hallgató által megszerzett pontokat, amelyek alapján végül összeáll a vizsgajegy. Fontos, hogy ezeket az adatokat olyan formában tároljuk az adatbázisban, hogy egy újabb számonkérésfajta bevezetése vagy egy meglévő formai átalakítása az adatbázis szerkezetének módosítása nélkül azonnal tükrözhető legyen a tárolt adatokban. Ennek érdekében az eredményeket három egymáshoz kapcsolódó entitással írjuk le.
Az egyes pontszámok különböző számonkérés-típusokhoz kapcsolódnak (ilyen a ZH, a vizsga és a házi feladat is), amelyeket egységesen egy-egy eredmény entitással írunk le. Az esemény entitás két attribútuma mellett továbbiakra általában nincs szükség, az esetleges járulékos információkat attribútumok segítségével adhatjuk meg. Ilyen lehet például a beadott NHF-programok futási ideje - akár tesztesetekre lebontva -, a generált naplóállományok elérési helye, vagy a gyakorlás során a hallgató által adott megoldások listája.
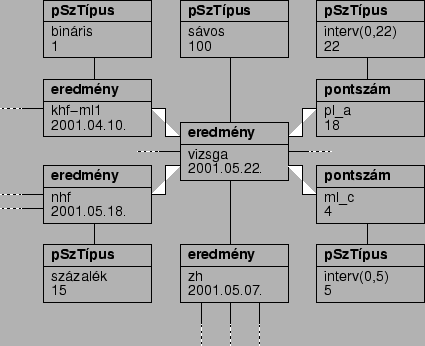
Az eredmények olyan események, amelyek kapcsolódhatnak más eredményekhez is, ilyenkor a fő eredmény összpontszámába be kell számítani az aleredmények összpontszámait is. (Ezzel a módszerrel remekül le lehet írni a vizsgát, amelynek eredményébe nem csak az aznapi teljesítmény számít bele, ld. fig:dbex. ábrát.)
Az eredményeket alkotó pontszámokat egy-egy pontszám entitás definiálja, a két entitást összekapcsoló reláció ,,egy - több'' jellegű. Minden pontszámnak van egy
Mind a pontszámokhoz, mind az eredményekhez hozzárendelünk egy-egy pontszámtípust, amely megadja, hogy az adott pontszámot hogyan kell értelmezni, ill. hogy az eredményhez kapcsolódó pontszámokat milyen módon kell összegezni. Ezt a pSzTípus entitás definiálja.
Mit jelent a pontszámtípus fajtája? Ha az adatbázisban csak egy pontértéket tárolunk, annak értelmezése az adatokat feldolgozó programon múlik. Ezt célszerű elkerülni, ezért tároljuk a fajtát is:
E négy fajta segítségével minden ismert pontszámtípust le lehet fedni, sőt az egyes fajták között vannak átfedések. Alapvetően csak egész értékeket érdemes tárolni, fél pontok osztogatásának nem sok értelme van. Ha ugyanis finomabb felbontás szükséges, akkor semmi akadálya, hogy a maximális pontszám a korábbi duplája legyen.
A pontszámtípus súlya azt adja meg (mondjuk százalékban), hogy az adott pontszám milyen mértékben vesz részt egy eggyel magasabb szintű összpontszám kialakításában. Erre azért van szükség, mert előfordulhat például, hogy a ZH nullától százig pontozódhat, de a vizsga összpontszámának - legyen mondjuk ez is maximum száz - csak a harmadrészét alkotja. Ebben az esetben a ZH-ra kapott pontszámot természetesen el kell osztani hárommal. Ennek jelzésére szolgál a súly, amely itt 33 lenne.
fig:dbex. ábrán látható, hogy hogyan lehetne leírni a jelenlegi
vizsgát a fenti három entitással. Az ábrán nem látható a teljes adatbázis
vonatkozó része, csak egyes részletek, a bemutatás kedvéért.
A levél mint esemény bemutatását a következő szakasz végére hagyom, mert a harmadik fő csoport ismertetése nélkül nem tárgyalható.
Azok az események, amelyek nem sorolhatók a három konkrét kategória egyikébe sem, leírhatók egy általános esemény entitással, a járulékos adatok pedig attribútumként adhatók meg.
A tantárgyhoz tartozik egy levelezési lista, amelyet jelenleg a mailman nevű közismert Unixos levlista-gondozó programmal működtetünk. Erre a hallgatóknak külön fel kell iratkozniuk. Ha azonban amúgy is tároljuk az e-mail címüket, semmi akadálya annak, hogy a levelezési listát akár közvetlenül az adatbázisban tárolt címlista alapján működtessük. A lista nyilvántartásának középpontjában a levlista entitás áll, ennek mezői a következők:
A lista lényegét természetesen a listára küldött levelek jelentik, amelyeket ugyan szöveges állományokban tárolunk, de valami minimális információt az adatbázisban nyilvántartunk róluk, az esemény entitás egy harmadik fajtája segítségével.
A harmadik eseményfajtát tehát a levelezési listára küldött levelek alkotják. Leírásukra szolgál a levél entitás, amelynek az esemény entitástól örökölt azonosítójában megadhatjuk az adott levél sorszámát, a megfelelő relációval hozzárendelhetjük ahhoz a hallgatóhoz, aki küldte (ha hallgató volt), és további mezőkkel leírhatjuk
Egy bináris értéket tároló attribútum csatolásával azt is nyilvántarthatjuk a levelekről, hogy részét képezik-e egy FAQ-csoportnak: ide azok a levelek tartoznak, amelyek fontos és gyakran visszatérő kérdéseket feszegetnek. Ha lekérdezhető az ilyen attribútummal rendelkező levelek listája, akkor már meg is van oldva egy FAQ lap összeállítása.
Noha entitás-reláció diagramon ábrázoltam az adatokat, a megvalósításnak nem kell relációs adatbázison alapulnia. Igaz, kézenfekvőnek látszik valamely megszokott, SQL-t ismerő relációs adatbázis-kezelő alkalmazása, a teljes ETS Prolog-beli megvalósítása azonban más megoldást sugall. A SICStus Prolog könyvtárai között megtalálható egy olyan modul, amely az ún. Berkeley DB struktúrát támogatja. Ennek segítségével - az adatbázis létrehozásakor meghatározott funktorú - Prolog-kifejezéseket tárolhatunk indexelt állományokban. Mivel a szóban forgó adatbázis mérete nem túl nagy, nem jelent veszteséget az sem, ha esetleg a Berkeley DB hatékonysága rosszabb, mint mondjuk a PostgreSQL relációs és objektum-orientált adatbázis-kezelőé. (Ez puszta feltevés, nem végeztem méréseket e tekintetben.)
Az sem előírás a megvalósításkor, hogy az ábrán és a leírásban összekapcsolt entitások külön táblában (vagy Prolog-kifejezésben) legyenek. A sokat emlegetett Prolog-megvalósítás esetén lehetséges egy olyan megoldás is, hogy a tárolt kifejezésekben a megfelelő helyen egy-egy lista áll, amely természetesen akárhány részkifejezést tárolhat. Egy ilyen lehetséges Prolog-kifejezés látható fig:bdb. ábrán. Itt a regisztrációkat és az eredményeket, azaz azokat az eseményeket, amelyek pontosan egy hallgatóhoz kapcsolódnak, a hallgatót leíró student/7 funktorú kifejezés egy-egy argumentumában elhelyezett listában tároljuk. A pontszámtípusokat nem ebben a struktúrában tartjuk nyilván, hanem elkülönítve (ez az ábrán nem látszik), a két struktúra közötti kapcsolatot az eredmények azonosítói (nhf, zh stb.) jelentik. A levelezési listát nyilvántartó részek szintén nem láthatóak az ábrán.
Az adatbázis inicializálását a NEPTUN-ban tárolt tárgyfelvételi nyilvántartás alapján lehet elvégezni. Innen automatikusan kinyerhető a hallgatók neve és NEPTUN kódja. Az egyéni beállítások értelmes alapértelmezett értékkel inicializálódnak, ezután a hallgatók maguk állíthatják őket sec:db-adm. fejezetben bemutatandó webes felületen keresztül. A pontszámok természetesen fokozatosan kerülnek be az adatbázisba, ahogy az ETS egyes moduljai aktiválódnak.
Ahogy a fejezet bevezetőjében jeleztem, a cél egy olyan értékelő program megtervezése, amely egyaránt képes a jelenlegi nagy és kis házi feladatokat kiszolgálni, mindezt kényelmesen, könnyen konfigurálhatóan teszi, és lehetőséget hagy a házi feladatok palettájának további bővítésére is. Ehhez a jelenlegi struktúrát alapvetően újra kell gondolni, természetesen az évek során felgyülemlett tapasztalatok figyelembe vételével. Ennél a tervezési résznél érthető módon nem tekinthetek el attól, hogy programozási nyelvek oktatásáról van szó, de ha csak lehetséges, nem használom ki, hogy konkrétan mely nyelvek oktatásáról. Amint látni fogjuk, a tervezés során arra sem építek, hogy egy esetleges megvalósítás milyen eszközökkel, milyen programozási nyelven készül. A saját magam által elkészített és sec:hffeld. fejezetben bemutatott változat - a bevezetőben foglaltaknak megfelelően - Prologban készült.
Elsőként néhány fogalmat vezetek be, melyek megkönnyítik a tervek tiszta
formába öntését, majd azonosítom a komponens szolgáltatásait. Ezt követően
javaslatot teszek a komponens állományainak elhelyezésére egy logikus és
áttekinthető könyvtárszerkezetben, amelynek jelenlegi, a nagy házi
feladatok ellenőrzésére használt programegyütteshez alkalmazott változatát
már bemutattam fig:olddirst. ábrán (![[*]](crossref.png) . oldal).
Végül, de nem utolsó sorban ismertetem a komponens paramétereit és az
ezeken keresztül vezérelhető működését.
. oldal).
Végül, de nem utolsó sorban ismertetem a komponens paramétereit és az
ezeken keresztül vezérelhető működését.
Ebben a részben azokat a fontosabb fogalmakat tekintem át, amelyekre a továbbiakban sokat fogok hivatkozni. Bizonyos fogalmak esetében angol elnevezéseket is bevezetek; ezekre a megvalósításkor lehet szükség, ugyanis jobban kedvelem azokat a programokat, amelyek angol neveket használnak az eljárások és változók jelölésére, mert magyar nevek használata esetén ,,csúnyán'' illeszkedik a saját magyar névtér a könyvtárak angol névteréhez. Most pedig lássuk, melyek ezek a fogalmak!
Ahogy azt itm:hfdiff. oldalon pontokba szedve leírtam, a jelenleg használt házifeladat-ellenőrző KHF és NHF értékelő része között számos eltérés van. A cél most olyan szolgáltatások kialakítása, amelyek eleget tesznek mind a két tesztosztálynak, sőt ennél többre is képesek. Ebben a fejezetben azonosítom a szolgáltatásokat, és meghatározom, hogy milyen igényeket kell kielégíteniük.
Ezen szolgáltatások közül több küld üzeneteket a hallgatóknak. Hogy az üzenetek megfogalmazása, nyelvezete könnyen módosítható legyen, célszerű őket a komponens többi részétől elkülönítve tárolni. Bizonyos üzeneteket ki kell tölteni adatokkal, például a sorban várakozók számával. Ezek az adatok, ha úgy tetszik, az üzenetek paraméterei, ezért az ily módon elkülönített részeket ezentúl üzenet-sablonnak fogom nevezni.
Az elkészült házi feladatokat továbbra is egy erre a célra készítendő beadó-programmal kell beadni, amely továbbra is félévfüggő, hiszen tartalmazza a névsort, hogy a hallgatóknak csak kiválasztani kelljen saját azonosítójukat, ne beírni, így nincs valós esélye annak, hogy valamelyikük véletlenül elírja. Egy féléven belül azonban ugyanazt a programot kellene használni az összes feladat beadásához. Ez nem különösebben bonyolult, csupán fel kell készíteni a programot arra, hogy felismerje, melyik tesztosztályról van éppen szó, ezután megfelelően becsomagolja az adott állományokat, kiegészítse a szükséges információkkal, és postázza.
Az elektronikus levélként való beadás mellett érdemes létrehozni egy webfelületet is ugyanerre a célra. Ez a lap voltaképpen egy űrlap lenne, amelyen a hallgatónak egy listából ki kell választania a saját azonosítóját, a feladat típusát (azaz a tesztosztályt), és meg kellene adnia, hogy mely állományok azok, amelyeket be kíván küldeni. (A HTML szabvány szerencsére lehetőséget ad állományok feltöltésére is.)
A cél az, hogy az összes ilyen tárgyú levelet egyetlen program fogadja - ahogy a KHF-ek esetében most is van -, és így ne kelljen egy újabb feladat kiadásakor a fogadóoldal ezen részén is módosítani. Ehhez a levelek törzsében benne kell, hogy legyen a tesztosztály azonosítója. A programnak ezen kívül ismernie kell az egyes tesztosztályok beadási időszakát, és ezen az időszakon kívül nem szabad elfogadnia az ide érkező leveleket, sőt erről értesítenie kell a levelek feladóit is. Így megoldható, hogy a fogadóprogramot egyszer, a félév elején kelljen csak felparaméterezni, és aztán ne legyen szükség további változtatásokra - legfeljebb a beadási időszakok módosulása esetén.
A tesztelés tesztsoronként külön-külön zajlik. Erre azért van szükség, mert többször előfordult, hogy miközben még folyt az NHF beadása (próbateszteléssel), a háttérben már zajlott a korábban beadottak létraverseny-tesztelése. A próba és a létraverseny teszthez pedig nyilvánvalóan két külön tesztsor tartozik.
A tesztelő legnagyobb része állandó. Vannak azonban olyan részek, amelyek félévről félévre változnak. Ezek egy része csak a feladatosztálytól függ, mások a nyelvtől is. Ilyen nyelvtől függő pl. a keretprogram is, amely a hallgatók által beadott programot teljes értékű, futtatható programmá egészíti ki, gondoskodik a tesztesetek és a megoldás belső és nyelvtől független alakja közötti konverzióról, igény esetén méri a futási időt stb.
A KHF-eket csak egy-egy nyelven, míg az NHF-eket mindkét nyelven be kell adni, és ezt a tesztelőnek tudnia kell kezelni. Ennek általánosításaként elvárható, hogy akármelyik tesztosztályra megadható legyen, hogy mely nyelveken kell tesztelni. Ennek érdekében a tesztelő nyelvtől függő részeit megfelelően el kell különíteni. Előfordult párszor, hogy egy beadott NHF egyik felét újra kellett tesztelni. Ehhez az kell, hogy a tesztelőnek meg lehessen adni egy nyelvet egy adott hallgatóra vonatkozóan, a spool állományban. Az ilyen tesztelésből előállított napló érthető módon nem teljes, elhelyezésekor két lehetőség közül választhatunk. Vagy külön állományba írjuk (amelynek nevében is jelezzük, hogy melyik nyelvről van szó), vagy a már meglévő naplóállomány megfelelő részét írjuk felül, a többi részt meghagyva. Külön nyelvi naplóállomány létrehozásakor jobb a teljes naplót tartalmazó állományt törölni, hiszen egy része érvényét veszti, és félrevezető lehet. A meglévő napló módosításához viszont a tesztelőnek fel kell ismernie az egyes nyelvi részeket.
A tesztesetek elhelyezése is eltér a két tesztosztály esetén. Az NHF-ek esetében egy könyvtár külön állományai tárolják az egyes teszteseteket és a referencia-megoldásokat, míg a KHF-ek esetében egyetlen állomány egy-egy sorában van mindez az információ. (Természetesen minden tesztsorhoz tartozik egy ilyen könyvtár vagy állomány.) A tesztelőnek mindkét lehetőséget meg kell engednie bármelyik tesztosztály esetében, sőt elképzelhető olyan lehetőség is, hogy közvetlenül keretprogramba vannak beépítve a tesztesetek, ilyenkor a keretprogram meghívásakor egy argumentumban kell átadnia a tesztsor és a teszteset azonosítóját.
Az időlimitek kezelése is más és más. Az NHF-ek esetében tesztesetenként kell tudni állítani az időlimitet, mert lényegesen különbözik a számítási igényük, és a futási időt is mérni kell. A KHF-ek esetében a futási idő nem lényeges, és az időlimit is csak a végtelen ciklusok kivédése érdekében szükséges, mértéke majdnem teljesen közömbös. Ezért a tesztelőnek meg kell tudnunk mondani, hogy mérje-e a futási időt, és az időlimiteket is meg kell tudni határozni akár tesztesetenként, akár egységesen.
A programok ellenőrzésére is több séma van. Az egyik, hogy - a komponens tesztosztály-függő részét képező - különálló ellenőrző programot használunk, amely egy bizonyos formátumban várja a referencia-megoldást és a beadott program megoldását, és ezek egyezését vagy eltérését jelzi valamilyen módon. A másik lehetőség, hogy az ellenőrzést maga a keretprogram végzi el, ilyenkor a kimenete nem maga a megoldás, hanem közvetlenül az összehasonlítás eredménye. A harmadik lehetőség, hogy a tesztelőbe beépített ellenőrzőt használjuk. Ennek előnye, hogy csökken a tesztosztály-függő részek mérete, ugyanakkor eleget kell tenni bizonyos formai követelményeknek, és szükség van referencia megoldásokra is. A megoldás algoritmikus ellenőrzése csak a keretprogramba építve lehetséges.
A tesztelés végeztével a tesztelőnek adott esetben módosítania kell az adatbázist. Ehhez tudnia kell, hogy az adatbázis melyik mezője tárolja az adott tesztosztályra vonatkozó eredményeket.
A tesztelő azon részét, amely állandóan fut a háttérben és várakozik újabb programokra, teszt-démonnak nevezem. A Unix világban ugyanis démon (angolul englishdaemon) elnevezéssel szokás illetni azokat a programokat, amelyek folyamatosan futnak, és időnként felébredve elvégeznek bizonyos feladatokat.
Mint említettem, a teljes archívumot megőrizzük a félév során, azaz a programok összes beküldött változata megvan. Erre azért is szükség van, mert pl. minden évben előfordul, hogy egy-két hallgató az utolsó levelében elfelejti mellékelni a Prolog-megoldást, mert már korábban beadta a véglegesnek tekintett változatát. Az is megesik, hogy valaki kéri, ne a legutolsó változatot vegyük figyelembe, mert abba egy módosítás során belekerült egy olyan hiba, amit csak utólag vett észre. Ilyen esetekben jól jöhet, ha az ETS üzemeltetője könnyen ki tudja csomagolni a korábbi leveleket, és ily módon kézzel bele tud avatkozni a tesztelési folyamatba.
Az archívum egy idő után feleslegesen nagyra duzzadhat, és hosszú távon elegendő a legutolsó verziók tárolása. E célból praktikus egy olyan szolgáltatás, amely kitakarítja az archívumot, és csak a legfrissebb változatokat tartja meg.
A beküldött levél azonnali tesztjéről automatikusan kap értesítést minden hallgató, aki kérte. Az éles tesztelésről, amely pontokat ér, a jelenlegi változatban nem. Ugyanakkor nem lenne bölcs dolog az éles tesztelés során azonnal elküldeni az értesítéseket, mert előfordulhat, hogy valahol hiba csúszik a folyamatba. A legjobb megoldás az, hogy a tesztelés után, miután az oktató meggyőződött róla, hogy az eredmények rendben vannak, egyetlen paranccsal ki lehessen küldeni az értesítéseket az archivált naplóállományok alapján.
Mint említettem, Lukácsy Gergely hasonlóságvizsgáló programja nyelvfüggetlen, csak arra van szüksége, hogy egy megfelelő alprogram feltérképezze a vizsgálat tárgyát képező programok hívási gráfját. Ennek megfelelően a komponens egyik feladata az ilyen gráfok elkészítése lehet.
A komponensnek helyet adó könyvtárat három alkönyvtárra osztanám. Az egyikben magát a tesztkörnyezetet tárolnám, a másikban a spool állományokat, a harmadikban pedig az archívumot és azokat a könyvtárakat, amelyekben a hallgatók programjait teszteljük. Ezeken belül további könyvtárakat hoznék létre, fig:newdirst. ábra szerint.
Az ábrán a csúcsos zárójelekbe írt szavak a jelentésüktől függő állomány- vagy könyvtárnevet takarnak. <name> az adott hallgató nevéből és azonosítójából generált, jól olvasható, informatív de egyértelmű nevet jelent.
Szintén a megvalósításhoz választott programozási nyelven múlik, hogy a forrásállományok közvetlenül alkalmasak-e futtatásra (a nyelv interpretált, mint pl. a Perl, a Bash, vagy akár a Prolog vagy az SML), vagy le kell-e őket fordítani valamilyen köztes kódba (Prolog- és SML-programokkal ez is megtehető, ilyen formában gyorsabban tölthetők be). Az ilyen köztes kód leggyakrabban architektúra-függő, ezért az utóbbi esetben érdemes a bináris állományokat elkülöníteni, hogy a rendszer kényelmesen hordozható maradjon, és véletlenül se keveredjenek össze a különböző változatok. Ilyen elkülönítésre alkalmas például egy-egy, az adott architektúra nevét viselő alkönyvtár, de az is jó, ha ugyanezt a bináris állomány nevének végére egy ponttal elválasztva odaírjuk.
A nyelvi könyvtárakban (ml, pl) a keretprogram mellett található egy inicializációs állomány is, amely megadja, hogy az adott nyelv teszteléséhez
A sablonok a hallgatóknak szánt üzenetek formáját és az állandó szövegrészeket leíró állományok, amelyek formátuma nyilvánvalóan függ a megvalósítástól. Lehetnek szöveges állományok speciális karaktersorozatokkal a sablon mezőinek jelzésére, lehetnek egyszerű programok, amelyek argumentumként kapják meg a mezők értékét, vagy akár összefoghatjuk őket egyetlen Prolog-modulba, amelyben a sablonoknak predikátumokat feleltetünk meg.
Egy-egy spool állomány reprezentálja az egy tesztsorhoz tartozó, beérkezett de még feldolgozásra váró hallgatói levelek várakozási sorát. Alapvetően csak a hallgatók nevét (pontosabban nevéből és azonosítójából generált nevet) tárolja, de egy-egy névhez több opció is tartozhat:
A hallgatók neve mellett előfordulhat egy speciális név is (mondjuk halt), amely a teszt-démont futásának befejezésére szólítja fel. Ezzel az utasítással oldható meg, hogy a teszt-démon kilépjen, miután tesztelte egy spool állomány összes programját, ellenkező esetben ugyanis végtelen ciklusban kell várakoznia az újabb és újabb levelekre.
Több állomány és könyvtár zárolására szükség lehet a többszörös hozzáférés miatt. Egyfelől zárolni kell a spool állományokat, hogy a leveleket fogadó program és a tesztelő ne akarja egyszerre módosítani ugyanazt az állományt, hanem várják meg egymást. Másfelől zárolni kell az éppen tesztelt hallgatói könyvtárakat, hogy egy másik tesztelő ne írja felül az adott könyvtárat egy levél kicsomagolásával.
Valamilyen módon gondoskodni kell a beragadt zárak törléséről. Erre jó módszer lehet az, hogy a zárat létrehozó program beleírja a saját processz azonosítóját, ha pedig valamely másik program ellenőrizni akarja a zár érvényességét, nem kell mást tennie, mint megnéznie, hogy létezik-e ilyen azonosítójú processz. Kevésbé biztonságos megoldás egy zár-időlimit meghatározása, amelynek letelte után az adott zárat beragadtnak tekintjük.
Ahhoz, hogy a tesztosztályokat a leírtaknak megfelelően, egységesen tudjuk kezelni, megfelelő paraméter-rendszerre van szükségünk. A paraméterek megnevezése mellett egyúttal lépésről lépésre ismertetem az egyes részek pontos működési mechanizmusát is.
A beadó program valamilyen formában tárolja a névsort, a jelenlegi változat például egy a szkript végéhez csatolt, uuencode-dal ,,titkosított'' blokkban. Futtatásakor elsőként ellenőrzi, hogy minden részfeladathoz elérhetők-e a szükséges programok (zip, uuencode, mail stb.), ha valami hiányzik hibaüzenettel leáll. Ezt követően tájékoztatja a hallgatót a beadás formai követelményeiről. Ha minden rendben van, az aktuális könyvtár tartalma alapján megpróbálja felismerni, hogy melyik tesztosztályról van szó, majd ezt a hallgatóval is megerősítteti. Ezután kilistázza az elküldendő állományokat, és ismét megerősítést kér. Innentől kezdve beavatkozás nélkül végzi a munkáját: összetömöríti az állományokat (pl. zip vagy tar és gzip programok használatával), kódolja valamilyen 7 bites kódolóval (pl. uuencode), hogy biztosan átjusson a levelezőrendszeren, kiegészíti fejléc-információkkal (a hallgató neve, a tesztosztály kódja), majd elküldi a fogadóprogram beégetett e-mail címére.
Annak, hogy a levél melyik tesztosztályba tartozik, a törzsében megadott információkból kell kiderülnie. Az összes többi paramétert egyetlen állományban tárolhatjuk (ennek elhelyezése tetszőleges, de az elérési utat meg kell adni a program az elindításakor). Ezek a következők:
A fogadóprogram elsőször ellenőrzi, hogy a levél megfelel-e a formai
követelményeknek, ha nem, akkor értesíti a feladót a helyes beadás
módjáról. Ezután megvizsgálja, hogy az adott tesztosztályra vonatkozó
beadási időszakon belül vagyunk-e, ha nem, megfelelő értesítést küld a
hallgatónak (ehhez már az adatbázisban tárolt címét használja, nem pedig a
levélben szereplőt). Ha minden rendben, az aktuális félév, a levélből
kinyert tesztosztály és az ennek megfelelő tesztsor azonosítója alapján a
archiválja a levelet, és a spool állományt is frissíti, majd nyugtát küld a
hallgatónak.
A spool állomány neve azért opcionális, mert a tesztosztály és a tesztsor azonosítója alapján előállítható egy alapértelmezett név.
Ez a szolgáltatás egyesíti a beadó- és a fogadó-oldalt. Ahogy azt a szolgáltatások ismertetésénél is leírtam, a webes beadáshoz a hallgatónak egy HTML űrlapot kell kitöltenie, megadva minden szükséges adatot (a hallgató azonosítója és jelszava, a tesztosztály azonosítója, valamint a beadni kívánt állományok neve). Az adatok megadása után a szerver-oldali CGI programnak ellenőriznie kell azok helyességét.
Ha minden rendben van, a rendszer áttérhet a fogadó-oldali részfeladatokra. Ezen a ponton két lehetőség tárul elénk. Az egyik, hogy a feltöltött állományok ,,hagyományos'' módon, elektronikus levélen keresztül folytatják útjukat, a beadó program szerver-oldali futtatása után. A másik, talán egyszerűbb és feltétlenül hatékonyabb megoldás az, hogy a CGI program saját maga végzi el a további teendőket is, tehát ellenőrzi a beadási időszakot, majd a programot megfelelően összecsomagolva elhelyezi az archívumban és a spool állományban. Ebben az esetben a művelet nyugtázása sem levélben, hanem webfelületen keresztül történik.
Teszt-démonból több is futhat egyszerre, mindenesetre egy teszt-démon egyetlen tesztsorért felelős. Ez azt jelenti, hogy csak azokat a programokat kell tesztelnie, amelyeket a hozzá rendelt tesztsorra kell futtatni, ezeket pedig egy spool állományban kapja meg. Többek között ezt kell a paramétereknek is tükrözniük:
A teszt-démon működése a következő. Elsőként megvizsgálja a spool
állományt, ha ez üres, akkor adott várakozási idő után újra próbálkozik.
Ha a sorban van program, akkor a megfelelő opció megléte esetén
kicsomagolja a levelet, majd ezután sorra veszi az összes tesztelendő
nyelvet (akár opció, akár paraméter alapján). Minden nyelvre bemásolja a
megfelelő nyelvi állományokat a hallgató tesztkönyvtárába, összeszerkeszti
a programot, futtatja a megadott tesztesetekre, és gyűjti az eredményeket.
Ha valamelyik tesztesetre a program túllépi az időlimitet, kilövi, és az
esetet hibás megoldásnak tekinti. A tesztelésről folyamatosan naplót
készít, feltüntetve a futási időket és eredményeket. A nyelvi teszt
befejeztével kitörli az újragenerálható állományokat, majd továbblép a
következő nyelvre. A tesztelés befejeztével archiválja a naplót, és
elküldi a hallgató adatbázisba bejegyzett elektronikus címére, ha ezt a
hallgató kérte. Ezután kitörli a spool állományból a programot és veszi a
következőt. (Eddig azért nem törölhetett, mert ha tesztelés közben a
tesztelő futása megszakad áramszünet vagy hasonló hiba folytán, akkor az
adott program tesztelését újra kell kezdeni.)
A többi szolgáltatás lényegesen egyszerűbb, ezért nem látom értelmét, hogy
azok működését is elmagyarázzam lépésről lépésre. A levelek fogadásához és
a teszteléshez megvalósított rutinok, eszközök - esetleg kis módosítással
- eleve alkalmasak ezen kiegészítő szolgáltatások megvalósítására, csupán
a felhasználói felületet kell kialakítani. A komponens működtetését
alapvetően parancssori utasítások kiadásával képzelem, de megfelelő
autentikáció esetén egy webfelület távolról vezérelhetővé is teheti.
Az erről a komponensről alkotott tervem főként az oktatók által vázolt elképzeléseken alapul, de nagy hatással volt rá a gyakorlórendszer próbaváltozata is, amelyet két demonstrátor készített Perl nyelven, s ezt követően maguk az oktatók fejlesztettek tovább. Különösen igaz ez a program kezelői felületére, amelyet alaposan tanulmányoztam, szemben a programkóddal, amelyet csak felületesen, nagy vonalakban ismerek. Talán nem túlzás azt állítanom, hogy ez a legszerencsésebb állapot, mert így tudok ötleteket meríteni, de nem ragadok le egy-egy jelenleg alkalmazott megvalósítási eszköznél és ezek korlátainál. A rengeteg hasznos ötletért köszönettel tartozom a rendszer készítőinek, Berki Lukács Tamásnak és Békés András Györgynek, valamint a tárgy oktatóinak.
A komponens struktúrájának megtervezésekor ezúttal is igyekszem függetlenedni az adott tárgytól, és csupán a mondanivaló megvilágítása érdekében hozok helyenként egy-egy konkrét peldát. Mivel a modul létrehozásának az a célja, hogy a hallgatók gyakorolhassák vele tárgyi tudásukat, nagyon fontos, hogy a felülete felhasználóbarát legyen. Emellett természetesen az is fontos, hogy az oktatók át tudják tekinteni a belső struktúráját és relatíve könnyen tudják újabb feladatokkal és feladat-típusokkal bővíteni a rendszert. A továbbiakban is e két szempont szerint fogom csoportosítani a mondandómat: elsőként a felhasználói felületével kapcsolatos terveimet mutatom be, majd áttérek a belső szerkezetre, az adatok és információk szervezésére. Mielőtt azonban belevághatnék e két témába, meg kell határoznom, hogy hogyan csoportosíthatjuk a feladatokat.
A feladatokat programozási nyelvenként kétféleképpen tudjuk csoportosítani. Mindkét csoportosítás a feladatok egy-egy jellemzőjén alapul, ezek a következők lehetnek:
Az ETS programozásának szempontjából alapvetően a sémák szerinti felosztás hasznos. Egy sémába azok a feladatok tartoznak, amelyekhez ugyanolyan jellegű adatokat kell kérdezni a hallgatótól, és ezen adatok ellenőrzése is ugyanúgy zajlik. Érthető módon ez független a témakörtől, hiszen például programozási feladat esetében mindig egy rutint kell megírni, amit mindig valamilyen - a feladattal együtt meghatározott - bemeneti adathalmazon tesztelünk.
Felhasználói oldalról közelítve inkább a témakörök szerinti felosztásnak van értelme, mivel így lehet jól elkülöníteni a tananyag egymástól relatíve független részeit. Márpedig mindig könnyebb egy-egy kisebb önálló rész megértése, mint az összefüggő egészé.
A két tulajdonság tehát független egymástól, elméletileg akármelyik témakörben előkerülhet akármelyik séma. El tudok képzelni például listákkal kapcsolatos programozást, és listák kanonikus alakra hozását is. Természetesen bizonyos témakörök szűkítik az alkalmazható sémák körét.
Noha a tervezés során célom, hogy az ETS rendszer tárgyfüggetlen maradjon, a módszereket, fogalmakat időnként érdemes valós példákkal alátámasztani. Ezt teszem ebben az esetben is, amikor bemutatom, hogy a Deklaratív programozás című tárgy esetében milyen konkrét témaköröket és sémákat lehetne definiálni. A témakörök felsorolásakor megadom, hogy milyen sémákat rendelhetünk hozzájuk (a sémákra a tömörség kedvéért a betűjelükkel hivatkozom). Fontos megjegyezni, hogy ezek csak példák, a megvalósítás során csak egy alapos felmérés után szabad meghatározni a ,,végleges'' kategóriákat.
A programozás séma esetében lehet bizonyos megkötésekkel élni, pl. a klózok számát vagy a felhasználható, felhasználandó beépített rutinokat illetően, meg lehet adni előre bizonyos klózokat vagy segédeljárásokat, vagy elő lehet írni, hogy a megoldás jobbrekurzív legyen. Ezek a megszorítások akár a séma paramétereinek is tekinthetők.
A komponens jelenlegi megvalósításának felhasználói oldalát alapvetően kielégítőnek találtam, ezért apró változtatásoktól eltekintve nem módosítottam rajta. A felület weblapjai háromszintű hierarchiát alkotnak. A legkülső szinten, a bejelentkező lapon a hallgatói azonosítót és az adatbázisban tárolt jelszót kell megadni, így tudunk csak hozzáférni a további lapokhoz. A második szinten a hallgató nyomon tudja követni saját haladását egy táblázat segítségével, amelyben témakörönként meg van adva, hogy összesen hány feladattal próbálkozott idáig és hogy ezek közül hányat oldott meg sikeresen. Emellett azt is ki tudja választani, hogy most melyik témakör feladatait szeretné megoldani. Ennek technikai megvalósítására több lehetőség is kínálkozik. Vagy egy külön listában ajánljuk fel a választást, vagy a fenti statisztika egyes soraiban található egy-egy kereszthivatkozás is, amely elvezet az adott témakör feladataihoz. A legfontosabb persze a harmadik szint, a feladatok lapja, ennek tartalma a következő:
A lap tetején megjelenő üzenet elsősorban arra szolgál, hogy a legutóbb adott megoldásunk ellenőrzésének eredményét közölje. Legjobb esetben az áll benne, hogy a megoldás hibátlan, ezt követheti valamilyen magyarázat arra, hogy miért az (azok számára, akik találgatással jutottak el ide, és nem tudják, hogy lehetett volna kitalálni). Ilyenkor ugyanabból a témakörből kapunk egy következő feladatot. Az is lehet persze, hogy a megoldás rossz, ilyenkor az üzenet valamilyen módon rá kell hogy vezessen a hiba jellegére és helyére, és természetesen ugyanazt a feladatot kell visszakapnunk. A kényelem szempontjából fontos, ha az űrlap sem üres, hanem tartalmazza az előző megoldásunkat, és csak módosítani kell rajta. A lapalji hivatkozások arra az esetre kellenek, ha a hallgató nem boldogul az adott feladattal, elunja a témakört, vagy be akarja fejezni a gyakorlást.
Minden témakörhöz van egy teljesítendő keret is: egy adott számú feladat megoldása után a rendszer úgy ítéli meg, hogy az adott témakört kellően elsajátítottuk, és másik választását javasolja. Ez a keret szintén feltüntethető mind az összefoglaló táblázatban, mind a feladatlap tetején megjelenített statisztikák részeként. Természetesen egy-egy témakör gyakorlását meg kell engedni a keret teljesítése után is, ilyenkor elég figyelmeztetni a hallgatót. A témakör kiválasztásakor a döntés azzal is segíthető, ha a lapon más színnel van írva azon témakörök neve, amelyeket már teljesített az érintett hallgató.
Az előző szakasz alapján kiderült, hogy egyfelől nyilván kell tartani az egyes hallgatók haladását, másfelől különbözőképpen kell kezelni az egyes nyelveket és ezen belül az egyes feladat-sémákat.
A hallgatók eredményeit természetesen az adatbázisban tároljuk, de ugyanitt feljegyezhetjük a haladásukat is. Rendeljünk minden hallgatóhoz egy olyan entitást, amelyhez témakörönként egy-egy attribútumot rendelve nyilvántartjuk a jól és a rosszul megoldott feladatok listáját, és egy további attribútumban azt, hogy melyik témakörrel foglalkozott legutóbb. Igény szerint azt is bejegyezhetjük, hogy milyen megoldásokat adott az egyes feladatokra, akár a megoldás direkt tárolásával, akár egy naplóállományra való hivatkozás formájában. Ehhez persze újabb attribútumokra van szükség, amelynek neve összeállhat a feladat egyedi azonosítójából (témakör-azonosító + sorszám) és a kísérlet sorszámából (ti. hogy hanyadszorra próbálja megoldani az adott feladatot).
A sémák és témakörök kezeléséhez egy könyvtárstruktúra kialakítását látom célszerűnek. Ennek alapján - mint látni fogjuk - a komponens tárgyfüggetlen részét képező CGI szkriptek automatikusan ki tudják nyerni a lapon megjelenítendő és az adatbázisba beírandó információkat, anélkül, hogy külön konfigurációs állományra lenne szükség. A tervet, amely a jelenleg meglévő rendszer könyvtárstruktúrájának továbbfejlesztett változata, fig:gyak-dirs. ábra mutatja.
A csúcsos zárójelek közé írt nevek mind egy rövid, egyedi azonosítót jelölnek. A nyelvek esetében ennek nincs jelentősége, de a témaköröknél ez a rövid azonosító épül be például a feladatok egyedi azonosítójába is, a témakörön belüli sorszámmal együtt. A séma esetén azért fontos az azonosító, mert így kell rá hivatkozni a témakör-adatokat rögzítő állományon belül (ez hamarosan kiderül).
A témakörök adatait fig:gyak-dirs. ábrának megfelelően egy-egy állomány rögzíti. Ennek szerkezete megvalósítási kérdés, de az alábbi adatokat mindenképpen tartalmaznia kell:
A jelenlegi megoldásban egy feladat adatai egyetlen sort foglalhatnak el. Ez nem szerencsés, mert az eredmény igen nehezen tekinthető át. Praktikusabb olyan formátumot választani, amiben többsoros bejegyzéseket tárolhatunk, pl. XML5.1-t.
Egy séma adatait egy könyvtár állományaiban tároljuk. Az egyik ilyen állomány egy HTML sablon, amely az ilyen sémájú feladatok lapján megjelenítendő információk (ssec:gyakif. szakaszban lévő felsorolás 4-8-as pontjainak megfelelő adatok) sablonja. A sémafüggő részek természetesen fixen be vannak írva ide, míg a témakör- és feladatfüggő adatok helye csak jelezve van valamilyen módon (például speciális HTML tag-ekkel, amelyeknek amúgy nincs értelmük). A sablon legfontosabb része az űrlap. Az ebben elhelyezkedő mezők neve olyan kell, hogy legyen, hogy azt a tárgyfüggetlen CGI program felismerje, hiszen a mezők tartalmát át kell adnia az ellenőrző programnak, amely a séma-könyvtár másik állománya.
Az ellenőrző program megkapja az űrlap mezőinek tartalmát párosítva a mezőnevekkel, és a témakör-állományban elhelyezett referencia-megoldást vagy teszteseteket. Mindkét adatcsoportot egy-egy (vagy egyetlen közös) állományban célszerű átadni, mivel méretük ahhoz esetenként túl nagy lehet, hogy parancssori argumentumban kapja meg. Természetesen ebben az esetben az állomány(ok) neve az argumentum. A program a megfelelő tesztek elvégzése után a megoldás elfogadhatóságát (jó-e vagy sem) a kilépési kódjával jelzi, a standard kimenetére pedig kiírja a vizsgálat eredményét ismertető HTML üzenetet, amelyet a következő feladatlap tetején jelenít meg az őt futtató CGI program. Ebben közölheti például hibás megoldás esetén a hiba jellegét és helyét. Egy ilyen hibaüzenet akár részletes, intelligens analízis eredménye is lehet, amelyből nem csak az derül ki, hogy a hibát mi okozza, hanem az is, hogy ebből milyen ismeret hiányára lehet következtetni, ill. hogy ennek hol lehet utána nézni a jegyzetben.5.2
A példa megoldásokat témakörönként külön-külön a megfelelő könyvtár HTML állományaiban vagy akár összefogva egyetlen HTML állományban is elhelyezhetjük, azzal a feltétellel, hogy minden példához elhelyezünk egy HTML horgonyt. Ennek neve témakörönkénti HTML állományok esetén a séma azonosítója lehetne, közös HTML állomány esetén pedig a témakör- és a séma- azonosítójából állna össze. Ezeket a CGI program felismerheti, és ha olyan feladat lapját jeleníti meg, amelynek témakör-séma párjához van példa, akkor a lapon elhelyez egy kereszthivatkozást a példalap megfelelő horgonyára.
Érdemes lehet a példákat nem közvetlenül HTML-ben leírni, hanem valamilyen olyan formátumban (például TEXinfo-ban), amelyből szükség esetén nyomtatható változat is előállítható, így akár a jegyzetbe is könnyen be lehet őket emelni.
Az eddigi információk alapján már nem okozhat meglepetést a működés ismertetése. A CGI állomány először is belépteti a hallgatót a jelszó és az azonosító bekérésével. Ezután összegyűjti a témakörök nevét (a témakör-állományokból), a hallgató helyzetét, és megjeleníti a statisztikákat tartalmazó és témakör-választást felkínáló lapot.
A feladatlapok megjelenítése a legizgalmasabb feladat. ssec:gyakif. szakaszban leírt felsorolásnak megfelelően elsőként ki kell írni a legutóbbi akció nyugtáját - ez vagy az egyik ellenőrző program kimenete, vagy maga a CGI program állította elő (pl. ,,Sikeresen belépett a rendszerbe.''). Ezután következik a kiválasztott témakör neve és az erre a témakörre vonatkozó statisztikák. Ezen a ponton véletlenszerűen kiválaszt egy feladatot azok közül, amelyekkel a hallgató még nem foglalkozott. Ha ilyen nincs, akkor azok közül, amelyeket még nem sikerült megoldania. Ha ilyen sincs, akkor véletlenszerűen választ egyet. Majd betölti a kiválasztott feladat sémájának sablonját és a megfelelő információkkal kitöltve (feladat azonosítója, hivatkozás a példára, feladat leírása) ezt is kiírja. A lapot a szükséges kereszthivatkozásokkal zárja (másik példa, másik témakör, kilépés).
Az űrlap postázásakor egy állományba kimenti a tartalmát, egy másikba (vagy ugyanennek a végére) pedig a feladat megoldókulcsát, és az állomány(ok) nevével meghívja az ellenőrző programot. Még jobb lehet egy közös állomány helyett a program standard bemenetét használni erre a célra, mivel ekkor biztosan nem maradnak hátra átmeneti állományok. A kilépési kód alapján a CGI módosítja az adatbázis megfelelő bejegyzéseit (jól/rosszul megoldott feladatok listája, megoldás helye), és megjeleníti a program kimenetén kapott üzenettel kezdve a következő feladatlapot.
Ahogy azt sec:fokomp. fejezetben elmondtam, ez a komponens is alapvetően adminisztratív jellegű. Ezért feladatai és a következő szakaszban ismertetendő adatbázis-hozzáférést biztosító komponens feladatai között vannak átfedések. Amint látni fogjuk, ott is vannak olyan szolgáltatások, amelyek a ZH- és vizsgaeredmények lekérdezését és bevitelét támogatják. Ezekre nem is térek ki ebben a szakaszban. Minthogy azonban ezek mind a Weben keresztül érhetőek el, ismertetek néhány olyan hasonló szolgáltatást, amelyek parancssor-alapúak, bizonyos helyzetekben ugyanis hasznos lehet a szöveges hozzáférés is.
Az ígéretemnek megfelelően vázolom elképzeléseimet az automatikus ZH-sor generálással és javítással kapcsolatban is. Hogy ezekből mi valósul meg, az nagyban múlik a gyakorlati alkalmazhatóságukon, amelyről szintén ejtek pár szót.
Az adminisztratív teendők ismertetésénél időrendi sorrendben haladok, elsőként a ZH, majd a vizsga támogatásáról ejtek szót.
A jelenlegi félévben is valami hasonló rendszer működik: a javítók egy Prolog-kifejezésekből álló szöveges állományt küldtek az oktatóknak, akik az eredményeket így egy egyszerű programmal tudták összegezni. A módszer tovább fejleszthető az összegzés automatizálásával. A javaslatom egy elektronikus cím létrehozása, ahová a javítók beküldhetik ezeket az állományokat, ott egy program fogadja őket, ellenőrzi és az eredményekkel automatikusan frissíti az adatbázist. A manipulációk kivédése érdekében korlátozni lehet azon e-mail címek listáját, ahonnan a program elfogadja az adatokat. A fogadóprogram azt is megteheti, hogyha egy-egy hallgató minden adata5.3 beérkezett, akkor küld neki egy összesítést, amennyiben ezt az érintett kérte.
A speciális állomány előállításának megkönnyítéséhez érdemes írni egy offline űrlap-programot. Kísérleti jelleggel elkészítettem egy ilyen programot, amelyet az ingyenes GNU Emacs szövegszerkesztőben lehet használni. A programot app:form. függelékben mutatom be.
Ide sorolhatunk minden olyan szolgáltatást, amely a ZH- és vizsgasorok előállítását, a dolgozatok javításának megkönnyítését célozza. A jelenlegi ZH rendszerben az oktatók 2-4 csoport kérdéseit dolgozzák ki, a ZH-sor előállításában egy TEX sablonállomány segít. A csoportok számát lehet növelni, de a javításhoz szükséges idő, attól tartok, nem csökkenthető. Ha ugyanis számítógép javítja a ZH-sorokat, akkor be kell gépelni a hallgatók megoldását, és ez feltehetően időigényesebb, mint a kijavításuk.
Érdekes lehet egy olyan konstrukció, amikor nem két csoport van, hanem sokkal több, akár minden hallgató más-más feladatsort kaphat. Ehhez alapvetően egy tekintélyes méretű feladat-adatbázisra van szükség, amely minden feladattípusból tartalmaz kellően nagy számú példát. Ebből egy alkalmas program generálhatna - a TEX sablon felhasználásával - ZH-sorokat, feltüntetve rajtuk többek között a hallgató nevét és azonosítóját. A módszer előnye, hogy praktikusan lehetetlenné tenné a megoldások másolását. Hátránya abban rejlik, hogy feltehetően lelassul a javítás. Ha ugyanis egyazon feladatsort kell javítani valakinek, akkor előbb-utóbb automatikusan rááll a szeme a típushibákra, és nem kell minden alkalommal újra meglátnia az egyes megoldások mögött meghúzódó gondolatokat. Ha azonban minden dolgozat más feladatok alapján íródott, akkor minden dolgozatot külön kell megérteni is. Ebben segíthet egy olyan program, amelynek megadva a hallgató nevét vagy azonosítóját, előállítja a neki generált dolgozat megoldásait, és ismerteti a pontozási szempontokat és azokat a típushibákat, amelyek az egyes feladatoknál előjöhetnek. Ehhez persze az kell, hogy a feladat-adatbázis ezekre az információkra is kiterjedjen, a feltöltése tehát nem kis munka.
Jobban automatizálható a javítás, ha a ZH - vagy egy része - feleletválasztós. Ilyenkor a megoldókulcs alapján nagyon gyorsan lehet javítani, hiszen nem kell megérteni a hallgató gondolatmenetét. Az is igaz, hogy egy ilyen teszt sokkal felületesebb képet ad a hallgatók tudásáról, mint egy kifejtendő kérdéses feladatsor.
A jelenlegi pontozási szisztéma a következő: minden megoldás alapesetben megkapja a maximális pontszámot, és minden javítás, amely ahhoz szükséges, hogy hibátlanná tegye, pontlevonással jár. Elvben ez a módszer elég egzakt ahhoz, hogy automatizálni lehessen. Persze ehhez pontosan definiálni kellene az ,,egy javítás'' fogalmát, és találni kell egy módszert, amellyel megtalálhatóak ezek a javítások. Lukácsy Gergely a hasonlóságvizsgáló programjának ismertetésekor (Lukácsy, 2000) részletesen foglalkozik olyan algoritmusokkal, amelyek forrásprogramok távolságának megállapítására szolgálnak. Elképzelhetőnek tartok egy olyan pontozó algoritmust, amely ezekhez az algoritmusokhoz hasonlóan méri a hallgató megoldása és a referencia-megoldás távolságát, és ez alapján von le pontokat.
Gondot jelent természetesen az a nyilvánvaló tény, hogy általában egy feladatnak nem csak egyetlen jó megoldása létezik. Ez részben feloldható úgy, hogy nem egy, hanem több referencia-megoldás létezik, és a legkisebb távolságot veszi figyelembe a program, de még így is kicsi az esélye, hogy minden megoldást elfogadhatóan pontozzon. Sokkal jobb a helyzet azokban az esetekben, amikor valóban egy jó megoldás létezik, mint például az SML-típusegyenletek vagy a Prolog-egyesítések esetében.
Ha feltesszük, hogy létezik egy ilyen automatikus pontozó, akkor is elgondolkodtató, hogy mely feladatoknál érdemes használni. Egy típusegyenletet például - a helyes megoldás ismeretében - gyorsan ki lehet javítani, feltehetően gyorsabban, mint amennyi ideig a begépelése és a javítás visszamásolása tartana. A programozási feladatok esetében már több értelme lenne, ott viszont az előző bekezdésben vázolt problémával szembesülünk. Összefoglalva elmondható tehát, hogy egy ilyen pontozóprogram elvileg ugyan kellemes megoldás lehet, a gyakorlatban azonban nem elég praktikus ahhoz, hogy érdemes legyen vele behatóbban foglalkozni, főleg ha tekintetbe vesszük, hogy megvalósítása egyáltalán nem rutinszerű feladat.
Az összes komponens közül talán ez igényli a legkevesebb tervezést. Voltaképpen nem kell mást tudnia, mint különböző lekérdezéseket megfogalmaznia és az eredményeket jól olvasható formában prezentálnia, célszerűen egy HTML lapon. A lekérdezések egy része csak olvas az adatbázisból, mások módosítják is. Mivel a komponens a Weben keresztül tartja a kapcsolatot a felhasználókkal, érdemes CGI programként megvalósítani. Az alkalmazott programozási nyelv megint csak közömbös, ha a specifikációt betartja, de ha az adatbázis a javaslatomnak megfelelően a Prologhoz illesztett Berkeley-rendszerben valósul meg, akkor érdemes ezt a programot is Prologban írni. A SICStus rendszer ráadásul támogatja Prolog CGI programok írását a Spanyolországban kifejlesztett ún. Pillow moduljával. A fejezet hátralévő részében a legalapvetőbb lekérdezéseket definiálom. A fejezethez tartozó A. függelékben bemutatok néhány weblap-tervezetet is.
Ebben a szakaszban arról lesz szó, hogy milyen lekérdezéseket kell minimálisan tudnia a komponens egy megvalósításának. Az áttekinthetőség kedvéért osszuk ezeket három csoportra. Az elsőbe azokat sorolom, amelyekkel a hallgatók fordulhatnak az adatbázishoz, a másodikba a csak az oktatók által elérhető lekérdezések tartoznak, a harmadik csoport pedig a levelezési lista archívumával kapcsolatos.
Alapvetően minden hallgató csak a saját adataihoz férhet hozzá. A hitelesítés az azonosítójuk és egy, az adatbázisban tárolt jelszó bekérésével történhet. A jelszó alapértelmezésben jobb híjján üres. Szerencsére a BME esetében elmondható, hogy a hallgatók nem nagyon ismerik egymás NEPTUN azonosítóit, tehát kicsi az esélye az illetéktelen hozzáférésnek a jelszó módosítása előtt.
Elképzelésem szerint egy központi lapon keresztül kellene belépniük a hallgatóknak a rendszerbe azonosítójuk és jelszavuk megadásával, és ezután akárhány lekérdezést, módosítást eszközölhetnének újabb azonosítás nélkül. Ennek megvalósításához a CGI programozásban jól bevált eszközök állnak rendelkezésre.
Az oktatóknak hozzá kell tudniuk férni mindenhez, amihez a hallgatók hozzáférnek. Ehhez lehet definiálni például egy vagy több operátori jelszót, amellyel bármilyen azonosító esetében beenged, vagy itt is alkalmazható az a megoldás, hogy elsőként azonosítjuk az oktatót a jelszavával, majd ezután megengedjük neki, hogy az előbb vázolt lekérdezéseket tetszőleges hallgatói azonosítóval elvégezze. E mellett persze számos egyéb lekérdezésre szükség van az adatok karbantartásához. Minden esetben fontos az oktatók hozzáférésének naplózása, hogy az esetleges illetéktelen hozzáférések legalább utólag felderíthetők legyenek.
Ugyanez a lekérdezés persze nem csak a ZH eredményeinek beírásához használható, hanem bármely más számonkérési forma esetében is. Az is előnyös lehet, ha lehetőség van arra, hogy ne egy módosítható űrlapot kapjunk, hanem egy szöveges - és akár nyomtatható - táblázatot. Ilyenkor természetesen a számított összpontszámot is javasolt feltüntetni. Azon számonkérések esetében, amelyek eredményébe más részeredmények is beszámítanak - ez kiderül az adatbázis relációból -, fel kell tüntetni ezeket az áthozott eredményeket is, és esetleg egy-egy kereszthivatkozással lehetővé tenni, hogy az oktató részletes bontásban is megtekintse őket.
Hasznos, lehet az olyan összesítés, amelyben az egyes jelentkezések vannak felsorolva, és mindegyikhez meg van adva, hogy hányan jelentkeztek rá összesen.
Az az információ, amit a levelekről a listában tárolunk, a levelek sokféle csoportosítását teszi lehetővé. A lekérdezések mind egy-egy csoportosítást tesznek láthatóvá a felhasználó számára.
Amikor egy levél érkezik a lista címére, egy szűrőprogramnak archiválnia kell a levelet és minden érintettnek tovább kell küldenie. Emellett ki kell olvasnia a levélből a feladót és esetleg a tárgyát, és ezeket az adatokat az elhelyezésével kapcsolatos információkkal együtt be kell írnia az adatbázisba. A levél fejlécében elhelyezett referenciák és a tárgy alapján felderíthető az is, hogy melyik szálhoz5.4 tartozik, ezt relációval lehet jelezni.
A lehetséges listázásokban mindig megjelenik a dátum, a feladó és a tárgy, és egy kereszthivatkozás a levél törzsére.
Természetesen a fenti lekérdezések bemutatásával csupán lehetőségeket kívántam felvillantani. Ezeken túl számos más, hasznos lekérdezés is megvalósítható, csak a fantázia és az idő szab határt.
Hanák Dávid <dhanak@inf.bme.hu>