|
A CYK algoritmusról tényleg nagyon röviden
Az algoritmus egy alulról felfele történõ elemzést valósít meg.
Ahhoz, hogy
mûködjön az kell, hogy a nyelvtan Chomsky normál alakban (CNF)
legyen, azaz
a nyelvtanban csak
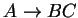 illetve
illetve
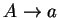 szabályok vannak (meg
esetleg az
szabályok vannak (meg
esetleg az
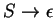 ,
de az most úgysem játszik).
Ha egy n hosszú ,
de az most úgysem játszik).
Ha egy n hosszú
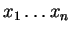 (ahol xi-k a betûk)
szót szeretnénk elemezni, akkor egy nxn-es
alsó háromszög
mátrix alakú táblázatot fogunk kitölteni a következõ módon.
A sorokat alulról felfele számozzuk, az oszlopokat balról jobbra.
Az i. sor j. kockájába akkor kerül a A nemterminálisa a
nyelvtannak, ha az A-ból levezethetõ az elemzendõ input szó
azon darabkája, ami a j. betûnél kezdõdik és i hosszan tart, vagyis
levezethetõ az
(ahol xi-k a betûk)
szót szeretnénk elemezni, akkor egy nxn-es
alsó háromszög
mátrix alakú táblázatot fogunk kitölteni a következõ módon.
A sorokat alulról felfele számozzuk, az oszlopokat balról jobbra.
Az i. sor j. kockájába akkor kerül a A nemterminálisa a
nyelvtannak, ha az A-ból levezethetõ az elemzendõ input szó
azon darabkája, ami a j. betûnél kezdõdik és i hosszan tart, vagyis
levezethetõ az
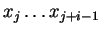 részszó.
Ha kitöltjük a táblázatot és a legfelsõ mezõben szerepel a
mondatszimbólum S az azt jelenti, hogy S-bõl levezethetõ
a szó az elsõ betûtõl az n.-ig, vagyis végig.
részszó.
Ha kitöltjük a táblázatot és a legfelsõ mezõben szerepel a
mondatszimbólum S az azt jelenti, hogy S-bõl levezethetõ
a szó az elsõ betûtõl az n.-ig, vagyis végig.
Ha az S nem jelenik meg a legfelsõ kockában, akkor a szó nem
eleme a nyelvnek.
A táblázat kitöltése:
Az elsõ sor egyértelmû: azok a nemterminálisok kerülnek a k.
mezõbe, akik egy lépésben a k. terminálist generálják egy
alakú szabállyal.
Késõbbi sorok: egy A akkor lesz az i. sor j. oszlopában, ha
belõle levezethetõ az
szó.
Mivel csak
alakú szabályok vannak ezért ez csak úgy lehet,
hogy a B megcsinálja
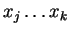 -t (az elejét, valameddig), a C
pedig -t (az elejét, valameddig), a C
pedig
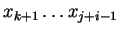 -et (a maradékot).
De ezt már le lehet ellenõrizni,
mert ezek az információk a táblázat már kitöltött részében benne
vannak. Tehát egy A-t akkor írunk be az i. sor j. kockájába,
ha van
olyan
szabály, hogy B benne van a j. oszlop k. sorában valami
k-ra, a C meg benne van a k+1. oszlop i-k. sorában. -et (a maradékot).
De ezt már le lehet ellenõrizni,
mert ezek az információk a táblázat már kitöltött részében benne
vannak. Tehát egy A-t akkor írunk be az i. sor j. kockájába,
ha van
olyan
szabály, hogy B benne van a j. oszlop k. sorában valami
k-ra, a C meg benne van a k+1. oszlop i-k. sorában.
Ha nem csak arra vagyunk kíváncsiak, hogy generálni lehet-e a szót,
hanem arra is, hogy hogyan, akkor nem csak a megfelelõ nemterminálist
írjuk be a táblázatba, hanem ellátjuk két indexszel is: az elsõ
mutatja, hogy milyen felbontásban generálja a BC sorozat a
szórészletet (azaz, hogy a B hány darab betû generál, ez a fenti
jelölésekkel a k),
a második meg annak a szabálynak a száma, amit használunk (vagyis az
szabály sorszáma, a szabályokat még az elején megszámoztuk, hogy
lehessen rájuk hivatkozni). Az elsõ index tulajdonképpen azt mutatja,
hogy az így beírt A oszlopában hányadik sorban kell keresnünk a B-t,
a szabály száma meg azt mutatja, hogy mit is kell keresnünk.
Így a levezetési fa felépíthetõ. Ha ezen visszakeresés során elágazást
tapasztalunk (azaz van olyan kocka, ahol két ugyanolyan, de más indexû
nemterminális áll), akkor a szó nem egyértelmûen áll elõ.
Ekkor a visszakeresõs eljárás mindkét levezetési fát megadja.
Egy példa végigszámolva, magyarázatokkal
itt.
|