|
|
A nagy zh egy jó megoldása
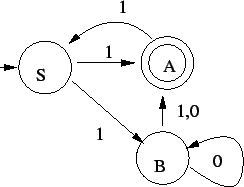
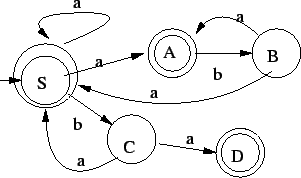
1. Az alábbi automata jó lesz:
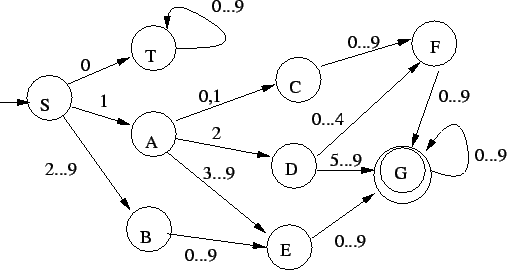
Az állapotok jelentései, ebbõl adódik, hogy mért jó az automata:
 : még nem olvastunk semmit : még nem olvastunk semmit
 nulla a szám eleje, azaz biztos elutasítunk nulla a szám eleje, azaz biztos elutasítunk
 : az elsõ jegy 1 : az elsõ jegy 1
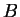 : az elsõ jegy 2-9 : az elsõ jegy 2-9
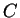 : a szám eleje 10 vagy 11, tehát még legalább két karakter kell az
elfogadáshoz : a szám eleje 10 vagy 11, tehát még legalább két karakter kell az
elfogadáshoz
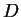 : a szám eleje 12, azaz szét kell majd választani két esetet a következõ
karakter szerint : a szám eleje 12, azaz szét kell majd választani két esetet a következõ
karakter szerint
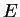 : a szám eleje 13, azaz elég már egy karakter az elfogadáshoz : a szám eleje 13, azaz elég már egy karakter az elfogadáshoz
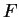 : az elsõ 3 jegy : az elsõ 3 jegy 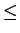 124, azaz még egy karakter kell biztosan 124, azaz még egy karakter kell biztosan
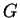 : elfogadó, vagy : elfogadó, vagy 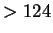 háromjegyû szám jött, vagy egy legalább négyjegyû háromjegyû szám jött, vagy egy legalább négyjegyû
Ez determinisztikus és egy kezdõállapotú, szóval pont, amilyen kell.
2. Az órán tanult algoritmus szerint eljárva:
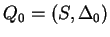 , ahol , ahol
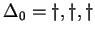
(A falaknál a visszatérõ állapotokat 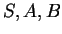 sorrendben sorolom fel, tehát
az elsõ helyen áll az -hez, aztán az -hoz, végül pedig a -hez
tartozó visszatérõ állapot.) sorrendben sorolom fel, tehát
az elsõ helyen áll az -hez, aztán az -hoz, végül pedig a -hez
tartozó visszatérõ állapot.)
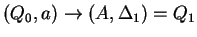 , ahol , ahol
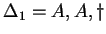
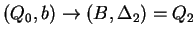 , ahol , ahol
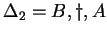
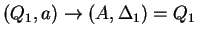
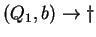
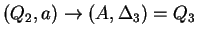 , ahol , ahol
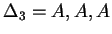
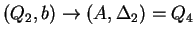
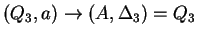
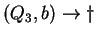
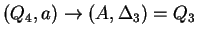
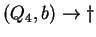
Tehát az egyirányú automata, ami determinisztikus és egy kezdõállapotú:
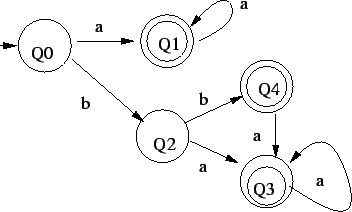
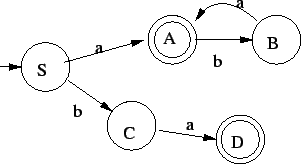
3. Elõször megfordítjuk a nyelvtant:
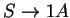 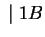
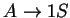 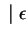
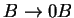 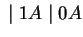
Ezután konstruálunk véges automatát ehhez a megfordított
nyelvtanhoz:
Ezután ezt az automatát visszafordítjuk, azaz a régi kezdõállapot lesz most
az elfogadó, a régi elfogadó állapot a kezdõ és minden nyilat fordítva húzunk
be:
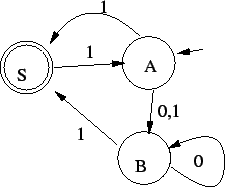
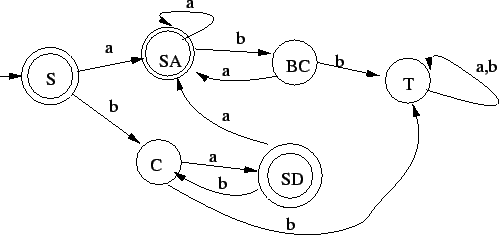
Ezt determinizáljuk és teljesen specifikáljuk:
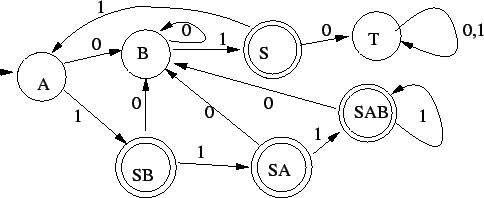
Ezt még minimalizáljuk, mivel minimálautomata kell:
A=1, B=2, SB=3, S=4, SA=5, SAB=6, T=7 számozással:
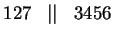
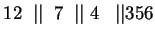
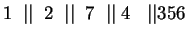
És ez már nem változik, tehát a minimálautomata:
4.
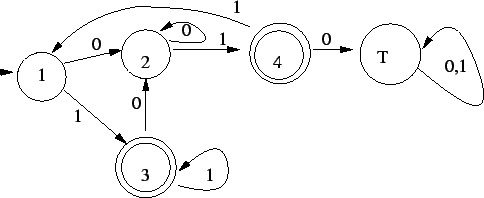
Elõször minimálautomatát adunk az elsõ reguláris kifejezéshez:
az 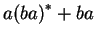 -hoz tartozó automata: -hoz tartozó automata:
Magyarázat ehhez:
-ban vagyunk, ha 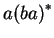 alakú szó jött eddig alakú szó jött eddig
-ben vagyunk, ha 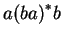 alakú szó jött eddig alakú szó jött eddig
-ben vagyunk, ha egy darab b jött eddig
-ban vagyunk, ha egy darab ab jött eddig
Ebbõl a tranzitív lezárt automatája, behúzva 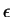 -nyilakat -bõl és
-ból -be és -et elfogadóvá téve
(nem kell új kezdõállapot, mivel a régi kezdõbe nem vezet
vissza nyíl): -nyilakat -bõl és
-ból -be és -et elfogadóvá téve
(nem kell új kezdõállapot, mivel a régi kezdõbe nem vezet
vissza nyíl):
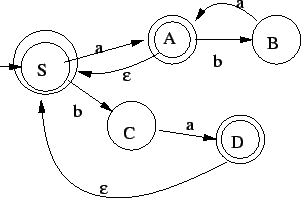
Az -szabályokat kiküszöbölve:
Ezt determinizálva és teljesen specifikálva:
Minimalizálva azt kapjuk, hogy az elfogadók összevonhatók és az
elutasítók is, kivéve a csapdát.
Így lesz a következõ automata:
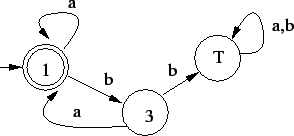
Vagyis az elsõ reguláris kifejezés azokat a szavakat írja le, melyekben minden
 után jönnie kell közvetlenül legalább egy után jönnie kell közvetlenül legalább egy 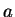 -nak. Másszóval amely szavakban
nincs kettõ egymás után és ahol a szavak nem is végzõdhetnek -re. -nak. Másszóval amely szavakban
nincs kettõ egymás után és ahol a szavak nem is végzõdhetnek -re.
Megmutatjuk, hogy a második reg. kif. is pont ezeket a szavakat írja le.
Vegyük észre, hogy a második reg. kif. ugyanaz, mint
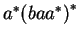 , hiszen
része , hiszen
része 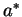 -nak és
-nak is. -nak és
-nak is.
Az
által leírt szavakban nem állhat két egymás után, mert
minden -t követ legalább egy és ugyanezért -re se végzõdhetnek a
szavak. Másrészt minden olyan szót, amiben nincs két egymás után és ami nem
végzõdik -re leír az
kifejezés, hiszen akárhány -t és a
-k után akárhány -t le tudunk tenni.
Tehát a két reg. kif. azonos nyelvet ad meg.
5. Az 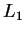 nyelv reguláris, amit az alábbi véges automata bizonyít: nyelv reguláris, amit az alábbi véges automata bizonyít:
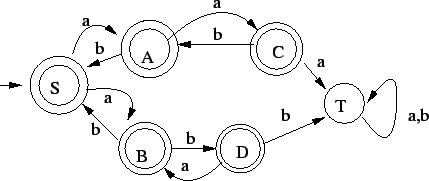
Az állapotok jelentése a következõ:
: eddig pont ugyanannyi volt, mint
: eddig eggyel több volt, mint
: eddig eggyel több volt, mint
: eddig kettõvel több volt, mint
: eddig kettõvel több volt, mint
: volt már rossz kezdõszelet, ahol túl nagy volt a különbség, innen már sose
fogadunk el, azaz csapda
Ez az automata pont a kívánt nyelvet fogadja el, hiszen csak arra
kell figyelni, hogy az eddig beolvasott szóban az -k és -k számának
különbsége 0, 1, 2, vagy több.
Az 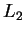 nyelv azonban nem reguláris, ezt a pumpálási lemmával igazoljuk.
Ha reguláris lenne, akkor létezne egy olyan nyelv azonban nem reguláris, ezt a pumpálási lemmával igazoljuk.
Ha reguláris lenne, akkor létezne egy olyan 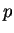 szám, ami a lemmában
van. Vegyük ezen -vel az szám, ami a lemmában
van. Vegyük ezen -vel az 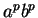 szót. Ez a szó -ben van és
hosszabb -nél. Jelöljük ki benne az szót. Ez a szó -ben van és
hosszabb -nél. Jelöljük ki benne az 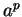 részszót. Mivel ez sem rövidebb
-nél, a lemma miatt ebben kell tudnunk találni egy olyan részszót, melyet
lehet ismételgetni úgy, hogy még mindig a nyelvben maradunk.
De -ben csak csupa -ból álló részszót tudunk találni, ha pedig azt
több, mint 3-szor megismételjük, akkor biztos több mint kettõvel több
lesz az -k száma a szóban, mint a -k száma. részszót. Mivel ez sem rövidebb
-nél, a lemma miatt ebben kell tudnunk találni egy olyan részszót, melyet
lehet ismételgetni úgy, hogy még mindig a nyelvben maradunk.
De -ben csak csupa -ból álló részszót tudunk találni, ha pedig azt
több, mint 3-szor megismételjük, akkor biztos több mint kettõvel több
lesz az -k száma a szóban, mint a -k száma.
|